Zusammenspiel von Millionen, manchmal sogar Milliarden sogenannter Neurone. Gehirn: schätzungsweise siebzig bis hundert Milliarden (ca.1011).
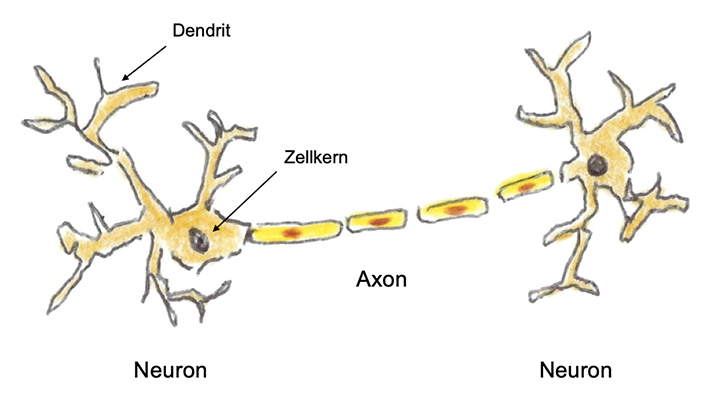
Skizze eines biologischen Neurons und einer seiner Verbindungen
Diese Informationsübertragung zwischen den Neuronen ist ein komplizierter elektrochemischer Prozess. Dabei spielen die Synapsen eine entscheidende Rolle.
Elektrische und chemische Synapsen: Erstere sind für schnelle, meist unwillkürliche Reizübertragungen zuständig. Chemischen Synapsen sind zuständig für alle komplexeren Vorgänge. Das Ende eines Axonsenthält eine Verdickung mit Vesikeln:
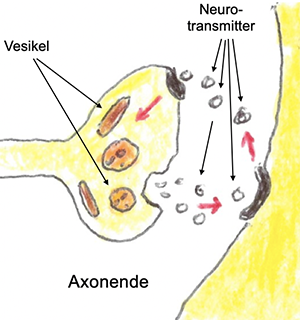
Reizübertragung durch den Synaptischen Spalt
kleine Bläschen, die chemische Botenstoffe enthalten, die Neurotransmitter. Kommt ein elektrischer Impuls am Ende eines Axons an, so werden solche Neurotransmitter ausgeschüttet.
Es gibt davon über hundert verschiedene. Sie überqueren den wenige Nanometer breiten sogenannten Synaptischen Spalt und können von Rezeptoren auf der Oberfläche eines Dendriten aufgenommen werden. Geschieht dies, so wird im Neuron das Aktionspotenzial ausgelöst, und es „feuert“, d.h. es sendet einen elektrischen Impuls aus. Dieses Feuern kann durch bildgebende Verfahren sichtbar gemacht werden.
Das Neuron ist elektrisch negativ geladen. Dies wird durch den unterschiedlichen Mix von positiven und negativen Ionen im Inneren des Neurons verursacht. Hauptsächlich handelt es sich dabei um Kalium-Ionen und Natrium-Ionen. Die elektrische Ladung des Neurons kann man messen.
Eine raffinierte Einrichtung, die sogenannte Natrium-Kalium-Pumpe. Sie sorgt dafür, dass diese Spannung im Ruhezustand erhalten bleibt. Ankommender Reiz öffnet die Natriumkanäle in der Zellmembran. Drei (positiv geladene) Natrium-Ionen strömen aus der Zelle heraus und zwei (ebenfalls positiv geladene) Natrium-Ionen hinein. Durch diesen Verlust einer positiven Ladung wird die Ladung des Neurons negativer.
Sobald ein Schwellenwert von -55 mV erreicht ist, werden ganz viele weitere Natriumkanäle geöffnet. Jetzt strömen viele positiv geladene Natrium-Ionen in die Zelle ein, und ihre elektrische Ladung wächst schnell bis ca. + 30 mV und kommt dann zum Stillstand. Das Neuron hat bereits vorher beim Überschreiten des Schwellenwertes einen starken elektrischen Impuls erhalten und über seine Nervenleitungen an alle mit ihm verbundenen anderen Neurone gesendet. Die Phase der schnellen Ladungszunahme nennt sich Depolarisierung.
Danach kehrt sich der Prozess um: Repolarisierung: Die Natriumkanäle werden geschlossen, die Kalium-Kanäle geöffnet. Positive Kalium-Ionen verlassen die Zelle, deren Ladung jetzt schnell wieder negativer wird. Die Natrium- und Kaliumkanäle werden dann wieder geschlossen. Dabei sind die Kalium-Kanäle träger als die Natrium-Kanäle, und die Ladung der Zelle schießt unter das Ruhepotenzial ins Negative. In diesen ein bis zwei Millisekunden, der sogenannten Hyperpolarisierung, darf die Zelle sich „erholen“, bis sie ihr Ruhepotenzial wieder erreicht hat. Erst jetzt ist das Neuron erneut in der Lage, Reize aufzunehmen und wieder zu "feuern". Der gesamte Vorgang dauert nur wenige Millisekunden und ist in der folgenden Abbildung schematisch wiedergegeben.
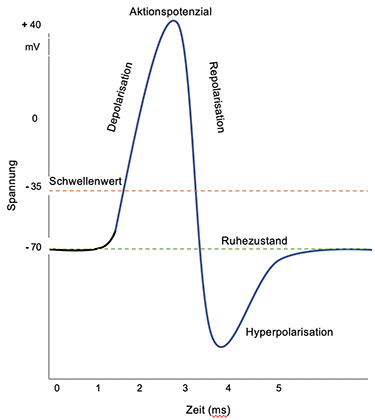
Auslösung eines Aktionspotenzials
Ein „erregtes“ Neuron kann seinen Impuls über viele Axone weiterleiten. Dabei sind immer Tausende bis Zehntausende Neurone aktiv. Die Stärke und Art eines übertragenen Reizes hängt von der Zahl der aufgenommenen Neurotransmitter ab. Diese
 |
Neurotransmitter |
| |
Wichtige Neurotransmitter sind z.B. Glutamat, Dopamin, Noredralin, Serotonin, Histamin und Oxytocin. Sie sorgen dafür, dass so unterschiedliche Dinge wie Lernen, Gedächtnis, Motivierung, Stimmung, Liebe, Vertrauen, Aufmerksamkeit, Wachsamkeit, Stress, Schlaf, Appetit und vieles mehr gesteuert werden. |
können verschiedene und unterschiedlich starke Wirkungen auslösen.
Die Synapsen verändern sich durch ihre Nutzung: Neubildung, Verstärkung oder Abschwächung - wichtig für das Lernen.
Dies beschreibt nur die „Basisprozesse“ im menschlichen Gehirn und ist noch in weiter Ferne, um die gigantische Gesamtleistung des Gehirns zu verstehen: Wahrnehmung, Gedächtnis, sich Erinnern, Lernen, Gefühle. Noch ungeklärt wie logisches oder assoziatives Denken oder Kreativität funktioniert.
Im Unterschied zu Computern verändert sich die „Hardware“ unseres durch unsere Erfahrungen, unser Denken und unsere Gefühle ständig. Gefühle sind eine mächtige Form der Codierung.
Alles dies macht deutlich, wie ambitioniert das Dartmouth-Projekt 1956 war, den Anstoß dafür zu geben, eine Maschine zu bauen, die das leisten soll, zu was der menschliche Geist fähig ist.
|

 tse Hamburg
tse Hamburg