Dr. Karl Schmitz
Künstliche Intelligenz - eine kurze Einführung
Überblick
Vorbemerkung
Unsere Arbeitswelt ist zurzeit großen Veränderungen unterworfen. Automatisierung betrifft immer mehr auch die Büroarbeit, die im Gegensatz zur industriellen Produktion bisher davon weitgehend verschont war. Die Corona-Krise hat mit einem Schlag auf breiter Front möglich gemacht, was vorher technisch und organisatorisch auch schon ging: das hybride Arbeiten. Die Arbeit ist für immer mehr Tätigkeiten und in immer mehr Bereichen nicht mehr an den Betrieb als Ort der Arbeit gebunden.
Das Vorpreschen von Microsoft als Finanzierer von ChatGPT hat der Künstlichen Intelligenz einen in seiner Heftigkeit unerwarteten Hype verschafft. Hunderte von Millionen Arbeitsplätze weltweit sollen in wenigen Jahren durch die neue Technik ersetzt oder einfach abgeschafft werden, glaubt man den Auguren[1] . Den Tech-Konzernen ist eine die Grenzen der Staaten übersteigende Macht zugewachsen, der die Politik noch recht hilflos gegenüber steht.
Als die Computer in - verglichen mit heute - gemächlichem Tempo in die Betriebe einzogen, in den späten 1970er und frühen 1980er Jahren, haben Gewerkschaften und Betriebsräte einen heftigen Aufstand organisiert. Ihr Widerstand richtete sich gegen die befürchtete Vernichtung der Arbeitsplätze, gegen gesundheitliche Schäden durch die Bildschirmarbeit, aber hauptsächlich gegen die drohende Überwachung - mit durchaus beachtlichen Erfolgen.
Heute, 50 Jahre später, kann man sagen, verhält sich die Auseinandersetzung um die Arbeit der Zukunft auf der Ebene der Betriebsparteien vorsichtig ausgedrückt umgekehrt proportional zur Heftigkeit der Änderungsrate, mit drastischeren Worten: sie findet nicht statt. Wichtiger Treiber der Veränderungen ist nach wie vor die Informationstechnik und ganz besonders die Künstliche Intelligenz, glaubt man der veröffentlichten Meinung .
Idee und Geschichte
![]() In der Literatur wird das Dartmouth Summer Reseach-Projekt von 1956 als Beginn der Künstlichen Intelligenz betrachtet. Den von den Stanford- und Harvard-Professoren John McCarthy und Marvin Minsky versammelten jungen Wissenschaftlern ging es darum, herauszufinden, wie man Maschinen bauen kann, die Sprache verwenden, abstrahieren, Begriffe bilden und Probleme lösen können, Dinge, die bisher nur menschlicher Intelligenz zugänglich waren. Das Problem ist nur: bis heute ist nicht wirklich geklärt, was man unter Intelligenz verstehen soll.
In der Literatur wird das Dartmouth Summer Reseach-Projekt von 1956 als Beginn der Künstlichen Intelligenz betrachtet. Den von den Stanford- und Harvard-Professoren John McCarthy und Marvin Minsky versammelten jungen Wissenschaftlern ging es darum, herauszufinden, wie man Maschinen bauen kann, die Sprache verwenden, abstrahieren, Begriffe bilden und Probleme lösen können, Dinge, die bisher nur menschlicher Intelligenz zugänglich waren. Das Problem ist nur: bis heute ist nicht wirklich geklärt, was man unter Intelligenz verstehen soll.
Als erster erkennbarer praktischer Fortschritt auf diesem anspruchsvollen Weg erschienen die Expertensysteme. Darunter sind regelbasierte Programme zu verstehen, die Schlussfolgerungen aus einer Datenbasis mit mühsam codiertem menschlichem Expertenwissen ziehen konnten. Sie bewegten sich stets innerhalb ihres Regelkreises, und das war ihr entscheidender Nachteil. Der Nutzen erschien außerdem in keinem vertretbaren Verhältnis zum Aufwand. Das Interesse an dem neuen Forschungszweig der Künstlichen Intelligenz ließ schnell nach.
Ein wichtiger Schritt nach dieser von Desillusionierung geprägten Eiszeit waren dann die Neuronalen Netze. Die ersten einfachen Lösungen gab es zwar auch schon in den 1960er Jahren[2], aber sie stießen schnell an ernüchternde Leistungsgrenzen. Die Idee war, die damals bekannten Abläufe im menschlichen Gehirn nachzubilden. Allerdings erst in den 1990er Jahren gelangen beachtenswerte Fortschritte, hauptsächlich weil man jetzt über neue Algorithmen und vor allem größere zugängliche Datenbestände verfügte. Die Grundidee war untereinander verbundene Speichereinheiten, die in einer Trainingsphase ihr Wissen lernen müssen, meist in Verfahren, in denen erfolgreiche Verbindungen verstärkt und weniger erfolgreiche abgeschwächt oder gar gelöscht werden.
Heute sind Neuronale Netze Teil des Maschinellen Lernens. Eine Untergruppe dieser Systeme wird große Erwartungen weckend oft als "selbstlernend" bezeichnet. Die Claims des augenblicklichen Hypes hat die junge US-amerikanische Firma OpenAI mit von Microsoft gesponserten Dollar-Milliarden am 30.11. 2022 gesetzt; an diesem Tag erblickte der Chatbot ChatGPT das Licht des Marktes und eroberte ihn in einem bisher nie dagewesenem Tempo. Google hatte zu lange Bedenken bezüglich der Sicherheit und Zuverlässigkeit, deswegen mit einen Produkten gezögert und erst Mitte 2023 seinen Chatbot BARD, inzwischen umbenannt in Gemini, auf den Markt gebracht. Die Chinesen stehen der westlichen Welt kaum noch nach, nur darüber erfahren wir wenig.
Die Grundlagen
Bei dem von Microsoft gesponserten Produkt ChatGPT handelt es sich um eine Software der Kategorie Large Language Model, abgekürzt LLM, ein auf Sprachverarbeitung spezialisiertes Neuronales Netz. Die dahinter stehende Technik wollen wir uns genauer ansehen.
Dabei ist die Technik nicht neu. Schon im März 2016 hate Microsoft einen ersten Chatbot names Tay auf Twitter in die Öffentlichkeit entlassen, aber nach wenigen Stunden Betrieb wieder zurückgezogen, weil er rassistische, sexistische und beleidigende Tweets produzierte. Der Startschuss für einen entscheidenden Fortschritt lieferten Google-Mitarbeiter 2017 mit ihrem Aufsatz „Attention is All You Need“[3]. das erste auf einem sogenannten Aufmerksamkeits-Algorithmus begründete Transformer-Modell. Google sah damals von öffentlichen Freigaben der darauf aufbauenden Produkte ab, weil die Technik für zu unsicher und zu unzuverlässlich gehalten wurde. Nach OpenAIs und Microsofts Vorpreschen mit ChatGPT wurde jetzt auf die Schnelle das Konkurrenzprodukt Bard herausgebracht. Meta, alias Facebook ist dabei, nachzuziehen. Schon im März 2023 hat die chinesische Firma Baidu ihren Chatbot Ernie[4] angekündigt und ihn im August 2023 in China öffentlich zugänglich gemacht.
Zu ChatGPT gibt es inzwischen rund ein Dutzend Varianten. Nahezu alle IT-Unternehmen überstürzen sich jetzt förmlich damit, in ihre Softwareprodukte Elemente Künstlicher Intelligenz einzubauten. Microsoft punktet mit der entsprechend aufgerüsteten Suchmaschine Bing und dem Produkt CoPilot. Die Hersteller traditioneller Unternehmenssoftware wie SAP oder Salesforce rüsten ihre Systeme nach. Wollte man die Szene beschreiben, so muss man sich bewusst sein, dass die Halbwertszeit der Darstellungen nur wenige Wochen beträgt.
Die Leitidee der Neuronalen Netze beruht weniger auf superintelligenten Algorithmen, sondern besteht darin, nachzubauen, was im menschlichen Gehirn passiert. Um besser zu verstehen, wie diese Technik funktioniert, leisten wir uns einen kurzen Ausflug in die Biologie. Dann wird deutlich, wie anspruchsvoll, vielleicht auch wie vermessen die Absicht ist, das in Jahrhunderttausenden von Evolution entstandene Wunderwerk der Natur nachzubauen.
Das menschliche Gehirn
Wir gehen davon aus, dass die Gedankenleistung unseres Gehirns das Ergebnis eines Zusammenspiels von Millionen, manchmal sogar Milliarden sogenannter Neurone ist. Davon verfügt unser Gehirn über schätzungsweise siebzig bis hundert Milliarden (in mathematischer Notation: ca.1011).
Neurone sind elektrisch erregbare Zellen, die für die Übertragung von Informationen im gesamten Nervensystem verantwortlich sind. Sie haben einen von einer Membran umgebenen Zellkörper, dessen Zellkern das genetische Material einer Zelle, die sog. DNA[5] enthält. Dieser Zellkörper hat zahlreiche baumartig verzweigte Fortsätze, die Dendriten. Sie können über sogenannte Synapsen Signale von anderen Neuronen empfangen. Über 500 Billionen solcher Synapsen hat ein menschliches Gehirn (5 x 1014). Untereinander sind die Neurone durch feste, gut isolierte elektrische Nervenleitungen, die Axone, verbunden. Diese sind in sog. Myelinscheiden verpackt, eine Isolation aus speziellen Lipiden (Fette) und Proteinen (Eiweiße) und dient zur Steigerung der elektrischen Leitfähigkeit der durch die Axone geleiteten Impulse.
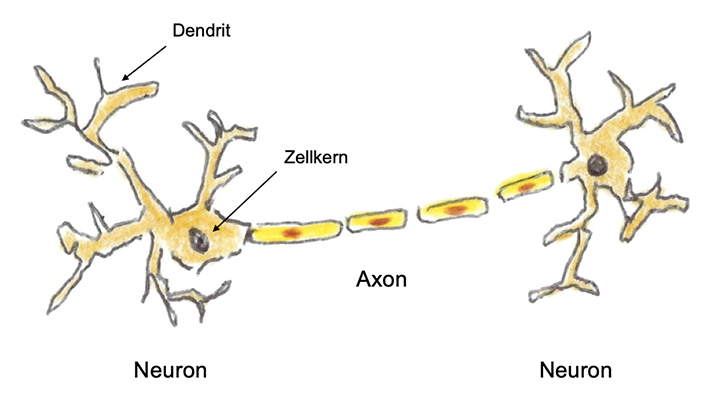
Skizze eines biologischen Neurons und einer seiner Verbindungen
Diese Informationsübertragung zwischen den Neuronen ist ein komplizierter elektrochemischer Prozess. Dabei spielen die Synapsen eine entscheidende Rolle.
Es gibt elektrische und chemische Synapsen. Erstere sind für schnelle, meist unwillkürliche Reizübertragungen zuständig, z.B. für die Steuerung der Lidbewegungen. Spannender sind die chemischen Synapsen, zuständig für alle komplexeren Vorgänge. Das Ende eines Axons, also einer Verbingungsleitung zu einem Neuron, enthält eine knöpfchenartige Verdickung mit Vesikeln.
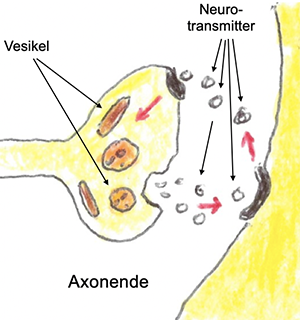
Reizübertragung durch den Synaptischen Spalt
Das sind kleine Bläschen, die chemische Botenstoffe enthalten, die Neurotransmitter. Kommt ein elektrischer Impuls am Ende eines Axons an, so werden solche Neurotransmitter ausgeschüttet. Es gibt davon über hundert verschiedene. Sie überqueren den wenige Nanometer breiten sogenannten Synaptischen Spalt und können von Rezeptoren auf der Oberfläche eines Dendriten aufgenommen werden. Geschieht dies, so wird im Neuron das Aktionspotenzial ausgelöst, und es „feuert“, d.h. es sendet einen elektrischen Impuls aus. Dieses Feuern kann durch bildgebende Verfahren sichtbar gemacht werden[6].
Das Neuron ist elektrisch negativ geladen. Dies wird durch den unterschiedlichen Mix von positiven und negativen Ionen[7] im Inneren des Neurons verursacht. Hauptsächlich handelt es sich dabei um Kalium-Ionen und Natrium-Ionen. Die elektrische Ladung des Neurons kann man messen[8].
Eine raffinierte Einrichtung, die sogenannte Natrium-Kalium-Pumpe, sorgt dafür, dass diese Spannung im Ruhezustand erhalten bleibt. Kommt nun ein Reiz an dem Neuron an, so werden Natriumkanäle in der Zellmembran des Neurons geöffnet, und drei (positiv geladene) Natrium-Ionen strömen aus der Zelle heraus und zwei (ebenfalls positiv geladene) Natrium-Ionen hinein. Durch diesen Verlust einer positiven Ladung wird die Ladung des Neurons negativer[9]. Sobald ein Schwellenwert von -55 mV erreicht ist, werden ganz viele weitere Natriumkanäle geöffnet. Jetzt strömen viele positiv geladene Natrium-Ionen in die Zelle ein, und ihre elektrische Ladung wächst schnell bis ca. + 30 mV und kommt dann zum Stillstand. Das Neuron hat bereits vorher beim Überschreiten des Schwellenwertes einen starken elektrischen Impuls erhalten und über seine Nervenleitungen an alle mit ihm verbundenen anderen Neurone gesendet. Die Phase der schnellen Ladungszunahme nennt sich Depolarisierung.
Danach kehrt sich der Prozess um; es beginnt die Repolarisierung: Die Natriumkanäle werden geschlossen und die Kalium-Kanäle geöffnet. Positive Kalium-Ionen verlassen daraufhin die Zelle, deren Ladung jetzt schnell wieder negativer wird. Die Natrium- und Kaliumkanäle werden dann wieder geschlossen. Dabei sind die Kalium-Kanäle träger als die Natrium-Kanäle, und die Ladung der Zelle schießt unter das Ruhepotenzial ins Negative. In diesen ein bis zwei Millisekunden, der sogenannten Hyperpolarisierung, darf die Zelle sich „erholen“, bis sie ihr Ruhepotenzial wieder erreicht hat. Erst jetzt ist das Neuron erneut in der Lage, Reize aufzunehmen und wieder zu "feuern". Der gesamte Vorgang dauert nur wenige Millisekunden und ist in der folgenden Abbildung schematisch wiedergegeben.
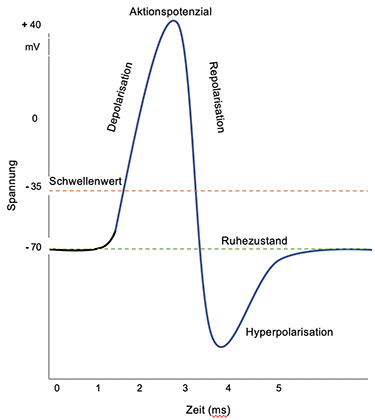
Auslösung eines Aktionspotenzials
Noch wichtig zu wissen: Ein „erregtes“ Neuron kann seinen Impuls über viele Axone weiterleiten. Es sind bei „normalen“ Vorgängen im Gehirn immer Tausende bis Zehntausende Neurone aktiv. Die Stärke und Art eines übertragenen Reizes hängt von der Zahl der aufgenommenen Neurotransmitter ab. Diese Neurotransmitter können verschiedene und unterschiedlich starke Wirkungen auslösen. Wichtige Neurotransmitter sind z.B. Glutamat, Dopamin, Noredralin, Serotonin, Histamin und Oxytocin. Sie sorgen dafür, dass so unterschiedliche Dinge wie Lernen, Gedächtnis, Motivierung, Stimmung, Liebe, Vertrauen, Aufmerksamkeit, Wachsamkeit, Stress, Schlaf, Appetit und vieles mehr gesteuert werden.
Die Synapsen im Gehirn verändern sich durch ihre Nutzung. Sie können sich neu bilden, den weitergeleiteten Reiz verstärken oder ihn abschwächen. Sie haben also eine wichtige Bedeutung für den Prozess des Lernens. Das komplexe System des menschlichen Wissens ist heute noch sehr unzureichend verstanden. Man darf aber annehmen, dass die Bildung der Synapsen und ihre Verstärkung bzw. Abschwächung dabei eine wichtige Rolle spielen.
Bisher haben wir nur die „Basisprozesse“ im menschlichen Gehirn beschrieben und befinden uns noch in weiter Ferne, um seine gigantische Gesamtleistung zu verstehen: die Wege von der Wahrnehmung in das Gedächtnis, der Prozess des sich Erinnerns und vor allem wie das Lernen funktioniert mit allen seinen Besonderheiten wie zum Beispiel die Spiegelneurone, die uns befähigen sollen, durch bloße Beobachtung anderer Menschen zu lernen oder die Indexneurone in den beiden Hippocampi als Schaltstelle zwischen Arbeits- und Langzeitgedächtnis. Wir können unterschiedliche Regionen im Gehirn bestimmen, die bei bestimmten Tätigkeiten aktiv werden, aber wie logisches oder assoziatives Denken vom Gehirn bewerkstelligt wird, wissen wir so gut wie nicht. Wir können auch nicht wirklich erklären, wie Kreativität zustande kommt.
Verglichen mit Computern haben wir soeben die Hardware unseres Gehirns beschrieben. Im Unterschied zu Computern verändert sich unsere Hardware durch unsere Erfahrungen, unser Denken und unsere Gefühle aber ständig. Wie sich Gefühle und das Erinnern an sie im Gehirn darstellt, wissen wir so gut wie nicht. Wir müssen aber konstatieren, dass Gefühle eine mächtige Form der Codierung sind. In für unsere Begriffe superschneller Form können ganze Dramen unsere Lebens in unserem Bewusstsein präsent werden, deren gedankliche Beschreibung nicht nur äußerst komplex sondern auch sehr langwierig wäre.
Alles dies macht deutlich, wie ambitioniert das Dartmouth-Projekt 1956 war, den Anstoß dafür zu geben, eine Maschine zu bauen, die das leisten soll, zu was der menschliche Geist fähig ist.
Künstliche Neurone
Wenigstens die Basisprozesse unseres Gehirns versucht man nun technisch zu simulieren. Selbst Pioniere der neuen Technik vertreten die Ansicht, dass das, was wir heute bauen können, bestenfalls eine Karikatur der Biologie darstellt. Jedenfalls ist es eine radikale Vereinfachung.
Wie die Darstellung der natürlichen Prozesse gezeigt hat, verfügt unser Gehirn mit seinen Neuronen, seinen Dendriten und Synapsen und den Axonen über eine sehr spezialisierte „Hardware“, die der heutigen Künstlichen Intelligenz nicht zur Verfügung steht - sie muss alles in Software simulieren.
So ist das Neuron der künstlichen Intelligenz ein softwaretechnisches Objekt, dem verschiedene Funktionen bzw. Methoden „anprogrammiert“ werden. Sie bestimmen, was das Neuron leisten kann. Die wichtigsten Funktionen sind:
- die Aktivierungsfunktion: Sie berechnet aus jedem Input des Neurons, was es entsprechend seinen besonderen Eigenschaften und Aufgaben tun kann bzw. soll.
- die Propagierungsfunktion: Sie fasst die Ergebnisse der Aktivierungsfunktion für die einzelnen Inputs zu einer Größe zusammen und berechnet somit, wie stark es die eingesammelten Impulse weitergibt, abschwächt oder ob das Neuron überhaupt nichts tut.
- Die Ausgabefunktion: Sie ist die Endstation für alles, was das Neuron verarbeitet hat. Sie kann die von der Aktivierungsfunktion berechnete Ausgabe nochmals verarbeiten oder das bisher erreichte Ergebnis einfach weiterleiten. Sie gibt das Ergebnis an die mit ihm verbundenen anderen Neurone weiter.
Es gibt unzählige verschiedene Methoden für die einzelnen der drei genannten Funktionen, die von der Art des Neuronalen Netzes, von seinem Anwendungsgebiet und vielen weiteren Parametern abhängen.
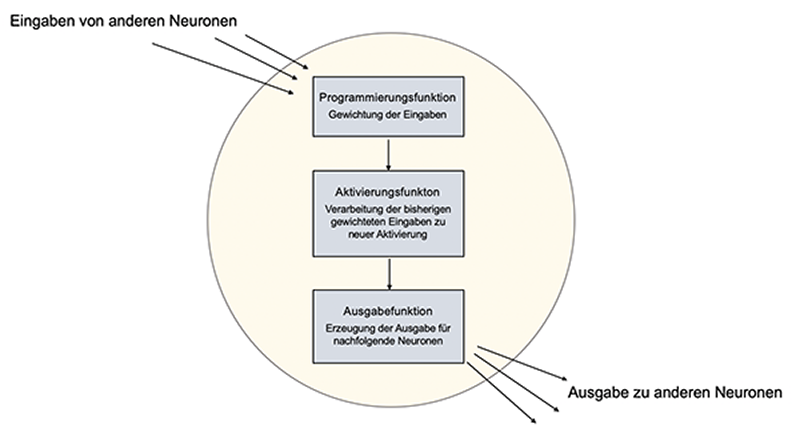
Die Signalverarbeitung durch ein Neuron
Die Funktionen nehmen ihre Bewertungen in der Regel durch Vektor-Multiplikation des am Neuron ankommenden Impulses mit einer nach ihren Algorithmen berechneten Zahl vor. Das kann eine Schwellenwertfunktion sein, d.h. das Signal wird nur weitergeleitet, wenn der Input einen bestimmten Wert hat bzw. überschreitet. Es kann - selten - eine lineare Funktion sein, ist meist aber eine nicht lineare Funktion, d.h. das Ergebnis ist nicht proportional zum Input. Alles das unterscheidet sich je nach der Aufgabe, für die das Neuronale Netz vorgesehen ist.
Netztopologien
Die Neurone sind nur die Bausteine, aus denen das Neuronale Netz aufgebaut wird. Sie können auf sehr unterschiedliche Weise untereinander verbunden sein. In der Literatur werden die Neurone oft als Knoten und ihre Verbindungen als Kanten bezeichnet. Die Verbindungen müssen natürlich auch softwaretechnisch simuliert werden. Ihre Stärke wird durch sogenannte Gewichte, oft eine Zahl zwischen 0 und 1, angegeben. Sie werden meist in einer Datenbank, selten direkt im Programm gespeichert und stellen mit den Funktionen der Neurone sozusagen das Gedächtnis des Neuronalen Netzes dar.
Zur Erinnerung: Der Vergleich mit der Biologie zeigt, wie dramatisch vereinfacht die technische Simulation ist. Der Vielzahl der unterschiedlichen von den Vesikeln am Ende der Axone infolge des dort ankommenden Reizes ausgeschütteten Neurotransmitter und ihren sehr unterschiedliche Wirkungen, die sie auslösen können, dem Übertragungsvorgang durch den synaptischen Spalt und dessen Veränderungen durch die Aktivität des Gehirns infolge des Erlebens, der Erfahrungen oder schlicht des Nachdenkens entsprechen im Modell des Neuronalen Netzes mathematische Funktionen und die Speicherung der Verbindungsgewichte. Unseren Erfahrungen entsprechen bei den Neuronalen Netzen oft zu wiederholende Trainings. Hier sehen wir deutlich, wie grob die technische Vereinfachung der biologischen Abläufe ausfällt.
Diese Gewichte sorgen dafür, wie stark ein Neuron seinen Output an ein anderes Neuron weitergibt. Das Netz selbst hat einen sehr einfachen Aufbau, es verfügt über
- eine Eingabeschicht: Hier enthält das Programm die zur Lösung seiner Aufgabe erforderlichen Informationen. Das kann ein Bild sein, auf dem bestimmte Dinge erkannt werden sollen, eine Anweisung, was eine gewünschte Geschichte oder ein Bild enthalten soll, ein Text, der in eine andere Sprache übersetzt werden soll, eine Anfrage, die das Netz beantworten soll oder ein beliebiges anderes elektrisches Signal. Der Eingabeschicht kann ein besonderes Stück Hardware vorgeschaltet sein, beispielsweise ein Kamerasensor, der das fotografierte Bild in Farbpixel übersetzt, ein Mikrofon, das die akustischen Signale in elektrische Impulse übersetzt oder ganz einfach eine Tastatur zum Eintippen von Text. Hauptsache, das was ankommt, ist digitalisiert.
- eine oder mehrere verborgene Verarbeitungsschichten, die sogenannten hidden layers. Hier findet die Verarbeitung der empfangenen Impulse statt. Das Neuron bedient sich dabei seiner oben genannten Funktionen und gibt nach getaner Arbeit sein Ergebnis an die anderen, mit ihm verbundenen Neurone weiter.
- eine Ausgabeschicht für die Darstellung des gewünschten Ergebnisses.
Die folgende Abbildung zeigt schematisch ein Neuronales Netz mit zwei verborgenen inneren Verarbeitungsschichten und Verbindungen, bei denen alle Neuronen mit einem Neuron der nachfolgenden Schicht verbunden sind. Nur das dritte Neuron in der ersten verborgenene Schicht in der Abbildung ist mit allen Neuronen der nachfolgenden zweiten verborgenen Schicht verbunden. Wie wir noch sehen werden, muss das nicht so sein. Je nach Bauart des Netzes gibt es verschidene Möglichkeiten, wie die Neurone miteinander verbunden sind, nur wie in der Abbildung vorwärts in eine Richtung oder auch zurück zu vorliegenden Schichten oder erneut zu sich selbst, um die bisher verarbeitete Information nochmals zu verarbeiten.
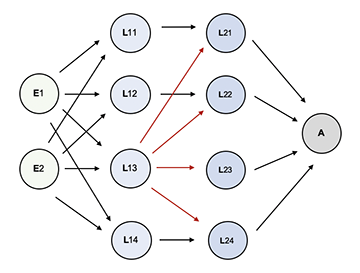
Schematischer Aufbau eines einfachen Neuronalen Netzes
mit zwei Eingabeneuronen (E), zwei hidden layers (L) mit je vier Neuronen und einem Ausgabeneuron (A).
Die Eingabeneuronen sind mit allen Neuronen der ersten Verarbeitungsschicht verbunden. Die Neuronen L11, L12 und L14 sind mit je einem Neuron, das Neuron N13 mit allen Neuronen der nachfolgenden Verarbeitungsschicht verbunden.
Im Laufe der Zeit wurden unterschiedliche Topologien Neuronaler Netze entwickelt, hier die unter dem Gesichtspunkt der Verbindungen zwischen den Neuronen wichtigsten:
- Feed-Forward-Netze: die einfachste Form, hier ist ein Neuron ausschließlich mit einem Neuron der Nachfolgeschicht verbunden. Die Information fließt also nur in eine Richtung.
- Rekurrente Netze: hier gibt es Rückkopplungen. Verbindungen können auch zu zurückliegenden Schichten, zu mehreren Neuronen, sogar zum betroffenen Neuron selbst führen. Dies ist z.B. nützlich für die Lösung von Aufgaben, bei denen die zeitliche Reihenfolge eine wichtige Rolle spielt sowie für Übersetzungen oder ganz allgemein Spracherkennung.
- Konvolutionale Netze: hier wird der Input in kleine Einheiten zerlegt, die dann mit vielen anderen Neuronen verbunden sind und die zerlegten Info-Teile wieder miteinander verknüpfen, ein übliches Verfahren für die Bilderkennung, Bildverarbeitung oder andere Varianten des sogenannten Maschinellen Lernens. Zuerst werden einfache Merkmale wie z.B. Kanten oder Ecken identifiziert, dann komplexere Strukturen, z.B. Gesichter. Danach werden die Informationen auf ihre wesentlichen Aspekte komprimiert. Die Leistung solcher Netzwerke kann durch spezielle Filterverfahren, die als Faltungen bezeichnet werden, weiter gesteigert werden; dadurch sollen z.B. Bildelemente oder ganz allgemein Objekte präziser erkannt werden.
- Es gibt noch eine Reihe weiterer Topologien, z.B. auf Graphen basierende Netze, in denen die Beziehungen von Dingen gemäß ihren Besonderheiten untereinander abgebildet werden.
Die Neurone können sparsame Verbindungen zu einzelnen spezialisierten Neuronen haben oder - im Extremfall - alle mit allen verbunden sein.
Die Large Language Models
Large Language Models machen nur einen kleinen Teil der KI-Landschaft aus, aber sie sind die Grundlage der Chatbots. Sie profitieren von den Methoden der Natürlichen Sprachverabeitung und sind Teil des Maschinellen Lernens, dem sog. deep learnig, bei dem viele verborgene Schichten eines Neuronalen Netzwerks verwendet werden. Dadurch sollen auch komplexe Muster in den für die Antworten verwendeten Daten erkannt werden.
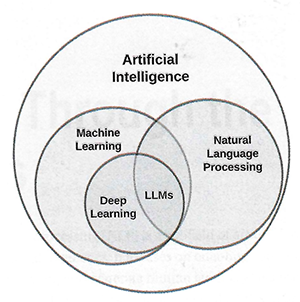
LLMs in der KI-Landschaft
Quelle:Thimira Amaratunga: Understanding Large Language Models, New York 2023
Im Unterschied zu den Expertensystemen sind es bei den Neuronalen Netzen nicht Algorithmen, die das „richtige“ Ergebnis finden. Ähnlich wie Menschen durch Erfahrung und insbesondere soziale Interaktion lernen, muss einem solchen KI-System durch Training beigebracht werden, was als richtig zu gelten hat.
Hier stellt sich die Frage: was soll überhaupt als „richtig“ gelten? Es geht nicht um Wahrheit, sondern um Nützlichkeit. „Wahr“ in diesem Sinne ist alles, womit die Nutzer zufrieden sind. Dafür wird eine Toleranzgrenze definiert. Diese beschreibt in Form einer Fehlergrenze die Genauigkeit, mit der das Netz arbeiten soll. Das Ergebnis resultiert also aus Statistik auf der Basis sehr großer Datenmengen (Big Data) und Wahrscheinlichkeitsrechnung.
Die Grundstruktur dieses Verfahrens ist recht einfach. Am Beispiel eines zu bearbeitenden Textes heißt das: Suche zu einem Wort das wahrscheinlichste nächste Wort, das dem gerade bearbeiteten Wort folgen kann. Dieser Wahrscheinlichkeitsberechnung steht der ganze Big Data-Pool mit wenn es sein darf Billionen und aber Billionen Wörtern zur Verfügung. Das ließe sich so fortsetzen, aber dann kämen recht bedeutungslose Sätze heraus. Also wird die Wahrscheinlichkeitssuche fortgesetzt mit der Suche, was am wahrscheinlichsten auf den gesamten bisher erzeugten Satz folgen könnte. Was mit einzelnen Wörtern funktioniert, geht natürlich auch mit Satzteilen oder ganzen Sätzen. Die Frage lautet dann: Was ist der mit höchster Wahrscheinlichkeit auf den bisherigen Satzteil folgende weitere Satzteil?
Das funktioniert nur, weil dem System ein Sprachmodell zugrunde liegt, ein sog. Large Language Model, abgekürzt LLM. In einem vieldimensionalen sogenannten Semantischen Raum wird jedes Wort durch einen Ort repräsentiert, auf den der Bedeutungsvektor des Wortes zeigt. Im Jahr 217 hat Google zuerst den Mechanismus vorgestellt, der dem ganzen Spiel zugrunde liegt, das Generative Pretrained Transformer Model, abgekürzt GPT. Generative steht für erzeugen, Pretrained ganz einfach für vortrainiert und Transformer für die Transformation, aus jedem Ausdruck per Statistik den wahrscheinlichsten Nachfolgeausdruck zu finden. Der dahinter steckende „Aufmerksamkeitsalgorithmus“ sorgt dafür, dass gefundenen Ausdrücken in dem Maße besondere Gewichte zuzgeordnet werden, in dem sie häufiger in der Nachbarschaft anderer Ausdrücke gefunden werden, ohne dass dafür ein manuelles Training erforderlich ist. Alles erfolgt maschinell, durch Auswertung der Häufigkeit gemeinsamen Vorkommens. So wird erreicht, dass die Orte in dem Semantischen Raum, auf die die Bedeutungsvektoren von Wörtern mit ähnlichen Bedeutungen zeigen, nahe beieinander liegen. Artikel, Präpositionen wurden natürlich anders behandelt als Wörter, die „echte“ Bedeutung tragen. Alles basiert auf Wahrscheinlichkeitsrechnung mit Zugriff auf very Big Data.
Obwohl Google sich zuschreiben kann, den Algorithmus „erfunden“ zu haben, hat es zu lange gebraucht, mit einem darauf fußenden Produkt auf dem Markt zu erscheinen. Dem Vernehmen nach waren es hauptsächlich Sicherheitsbedenken, die Google davon abhielten, sofort den Markteintritt zu suchen. Das System lieferte noch zu oft falsche Ergebnisse, ein Effekt, der später unter dem Begriff Halluzination verniedlicht wurde.
Ganz anders die kalifornische Firma OpenAI, die ihr Pretrained Model schnell zu GPT-4 bis Ende 2022 weiterentwickelt[10] hat und mit einer Zehn-Milliarde-Dollar-Spritze von Microsoft dann Anfang 2023 ihr ChatGPT auf den Markt gebracht und diesen in atemberaubender Geschwindigkeit erobert hat. Googles Chatbot-System Bard erblickte erst ein halbes Jahr später, Mitte 2023, das Licht des Marktes und wurde schnell in Gemini umbenannt.
So einfach wie hier beschrieben ist die hinter den Chatbots stehende Technik natürlich nicht. Eine genauere mathematische Beschreibung würde schon ein paar Dutzend Seiten füllen, die schnell sehr viel zahlreicher würden, wenn man alle dabei angewandten Tricks, Filter- und sonstige Methoden ausführlich beschreiben wollte.
Weil diese immensen Datenmengen lange nicht zur Verfügung standen, musste die Technik der neuronalen Netze Jahrzehnte auf ihren Durchbruch warten. Heute, Anfang 2024, gibt es eine Vielzahl von Large Language Models und darauf aufbauender Produkte; wir kommen noch darauf zurück.
Lernen und Trainieren
Für das Training der Systeme gibt es sehr unterschiedliche Strategien. Wir beschränken uns im Folgenden auf die wichtigsten.
Grundsätzliches zum KI-Training
Neuronale Netze müssen trainiert werden. Dazu sind riesige Datenmengen erforderlich, die auf ebenso riesigen Serverfarmen gespeichert sind. Das Verfahren läuft dann folgendermaßen ab:
- Zunächst muss der Aufgaben- bzw. Anwendungsbereich des Systems festgelegt werden. Was soll das System leisten? Welche Fragen sollen beantwortet werden? Am schwersten haben es hierbei die Systeme, die nicht nur für begrenzte Themen- oder Aufgabengebiete, sondern für alles zuständig sein wollen wie ChatGPT von OpenAI oder Google Bard.
- Für diesen Anwendungsbereich wird eine geeignete Datenmenge als Test-Domain ausgewählt. Sie soll repräsentativ für den gesamten Datenbestand sein und muss groß genug sein. Die Chatbots als universelle Systeme bedienen sich dabei bei den riesigen Datenbeständen der Wikipedia, digitalisierten Buchtexten und dem auch öffentlich zugänglichen Common-Crawl-Datenschatz der Suchmaschinen. Eine Reihe solcher riesigen Datenpools stehen öffentlich zur Verfügung. Welche weiteren Daten berücksichtigt werden, wird ein wichtiges Thema in den noch bevorstehenden Auseinandersetzungen um die Offenlegung der Trainingsquellen im Rahmen einer Transparenzforderung der Regulierer sein.
- Ein Teilbereich der Test-Domain wird als Input für das Training ausgewählt. Diese Daten müssen für die LLMs in verarbeitbare Form gebracht werden. Dafür gibt es Vektor-Datenbanken, die auch für die Speicherung nicht strukturierter Daten geeignet sind.
- Es werden Fragen oder Aufgabenstellungen definiert, zu denen man die als richtig geltenden Antworten kennt, erstellt hat und parat hält. Das können durchaus ein paar hundert Experten sein, die sich ein paar zigtausend ausgewählte für repräsentativ gehaltene Fragen und Antworten ausgedacht haben.
- Der Output der Bearbeitung durch das System wird mit den „richtigen“ Antworten abgeglichen, maschinell oder durch Testpersonen. Die komplette Prozedur wird solange wiederholt, bis die Abweichungen die vorher festgelegte Fehler- oder Ungenauigkeitstoleranz unterschreiten.
Danach kann das System mit den Daten der gesamten Trainings-Domain ausprobiert werden. Ist man mit den Ergebnissen zufrieden, wird das System der vorgesehenen Kundschaft zur Verfügung gestellt, in der Annahme, dass es jetzt auch für ähnliche Fragen und Aufgaben außerhalb der Trainingsdaten einigermaßen „richtige“ Ergebnisse liefert.
Die Aufgabe der Neurone im Netz ist immer nur die Antwort auf die Frage, was das wahrscheinlichste „richtige“ Ergebnis ist, immer nur für die spezielle Aufgabe. Soll das Neuron z.B. in den Pixeln einer Bilddatei Kanten oder Ecken erkennen, so vergleicht es die Pixelmuster seines Inputs mit den Pixelmustern von Kanten oder Ecken, auf die es trainiert wurde und ermittelt eine Wahrscheinlichkeit für die Aussage, dass es in dem Eingabemuster eine Kante oder Ecke findet.
Dem Neuron ist ein Schwellenwert zugeordnet. Es wird nur aktiv, wenn der ankommende Input diesen Schwellenwert erreicht oder überschreitet.
Die Verbindungen der Neurone untereinander werden mit Gewichten versehen; diese beschreiben sozusagen die Stärke der Weiterleitung seines berechneten Ergebnisses, in der Regel eine positive Zahl für als brauchbar erachtete Ergebnisse. Eine Null bringt das Neuron zum Schweigen, und eine negative Zahl würde dem Netz signalisieren, dass es sich hier auf dem Holzweg befindet. Mit dieser Zahl wird das Ergebnis multipliziert und dann weitergeleitet.
Für die Durchführung der Gewichtbewertung stehen dem Neuron die Algorithmen aus seinen Aktivierungs-, Propagierungs- und Ausgabefunktionen zur Verfügung. Hier wird also „gerechnet“.
Diese Gewichte sind es auch, die im Training der Systeme nochmals verändert werden. Wird z.B. die Antwort des Systems auf eine Trainingsfrage als falsch bewertet (maschinell oder manuell durch eine Testperson), so werden die betroffenen Gewichte der Neuronenverbindungen um einen kleinen Betrag herabgesetzt.
Der Trainingsprozess ist nichts weiter als trial and error oder besser Zuckerbrot und Peitsche. „Gute“ Ergebnisse werden „belohnt“, sprich verstärkt, schlechte „bestraft“, sprich die Verbindungsstärke wird abgeschwächt oder sogar auf Null gesetz. Das Verfahren mit dem Trainingsinput wird so lange wiederholt, bis der Output dem gewünschten Ergebnis zufriedenstellend entspricht. Dies wird dann durch Unterschreiten einer vorher bestimmten Fehlertoleranz festgestellt.
Aus der Wahrscheinlichkeitsrechnung wissen wir, dass die Zuverlässlichkeit einer Prognose, also die Signifikanz des Ergebnisses, extrem stark von der Größe der Datenmenge abhängt. Auf diese Erkenntnis stützt sich die Hoffnung auf gute Ergebnisse auch mit Daten, die nicht in den Trainingsdaten enthalten waren. Man verlässt sich einfach darauf, dass wegen der Terabyte von Trainingsdaten für ähnliche Daten auch brauchbare, hochwahrscheinlich „richtige“ Ergebnisse geliefert werden. Der Wahrheitsbegriff ist, wie bereits erwähnt, durch einen Nützlichkeitsbegriff ersetzt worden.
Für sein Lernen stehen dem System mehrere Möglichkeiten zur Verfügung:
- neue Verbindungen herstellen,
- vorhandene Verbindungen löschen,
- Verbindungsgewichte zwischen den Neuronen verändern,
- Schwellenwerte verändern,
- eine oder mehrere der drei Neuronfunktionen verändern,
- neue Neurone in das System aufnehmen und/oder
- vorhandene Neurone löschen.
Die gängigste Lernmethode ist die Veränderung der Gewichte, also die Stärke der Verbindungen zwischen den Neuronen. Sie benötigt keine Eingriffe in die Programmierung und kann allein durch das Training bewerkstelligt werden.
Wer länger mit KI-Chatbots gearbeitet hat, wird bemerkt haben, dass die Ergebnisse sprachlich überarbeitet sind. Die (meisten) Systeme sind darauf ausgerichtet, dass verletzende, Gewalt verherrlichende oder zu Gewalttaten auffordernde Ergebnisse unterdrückt werden, sollten sie in den Daten gefunden worden sein. Dafür stehen Filter, spezialisierte Algorithmen und besondere Trainings mit eigens für die Beurteilung der zu unterdrückenden Antworten aufbereitete Datensätzen zur Verfügung. Teile dieser Arbeiten können computerunterstützt erfolgen, z.B. durch bestimmte Tests, aus denen sich spezialisierte Trainingsfragen erzeugen lassen.
Der Dark Factor-Test z.B. ist ein Persönlichkeitstest, der psychologische Dunkelseiten eines Menschen, und zwar psychopathisches Verhalten, Narzissmus und, wie es heißt, Macchiavellismus misst[11]. Ähnlich werden auch die Filter für political correctness aufgebaut oder für Deutschland das Verwenden des Genderns.
Trainingsmethoden
Ganz grob kann man die folgenden Trainigsmethoden unterscheiden:
- Überwachtes Lernen (Supervised Learning): Das Netz arbeitet mit sehr vielen ihm bekannten Eingabe- und Ausgabemustern. Für die zum Training ausgewählten Daten kennt das System für jeden Input den „richtigen“ Output und vergleicht für jeden einzelnen Trainingsschritt das vorhergesagte Ergebnis mit dem „richtigen“ Ergebnis. Es ändert dann die Gewichte zwischen den Neuronen selbständig gemäß bestimmter Verfahren (sog. Loss-Funktionen) und lernt so die Eingabemuster mit den gewünschten Ausgabemustern mit jedem Schritt besser zu verbinden. Die Daten müssen hohe Anforderungen an ihre Qualität erfüllen und gelabelt sein, d.h. jedes Datenbeispiel in den Trainingsdaten muss mit besonderen Merkmalen näher beschrieben sein.
- Unüberwachtes Lernen (Unsupervised Learning): Das Netz erhält keine Eingabehilfen und muss versuchen, selbst Muster oder Eigenschaften in den Daten zu finden, ohne vorher zu wissen, wonach es suchen soll.
- Bestärkendes Lernen(Reinforcement Learning): Das Netz erhält im Vergleich zum überwachten Lernen deutlich weniger Informationen. Es muss die passende Kategorisierung der Eingabe selber herausfinden und erhält nach jedem Durchlauf nur die Information, ob sich die Richtigkeit des Outputs verbessert oder verschlechtert hat. Aufgrund dieser Information ändert es die Gewichte zwischen den Neuronen, ebenfalls nach bestimmten, je nach Verwendungszweck des Netzes unterschiedlichen Verfahren.
Oft empfiehlt es sich, die Trainingsmenge in eine kleinere Menge für das eigentlche Training zu teilen und den größeren Rest für die Bewertung des Traininsfortschritts zu verwenden.
Der zeitliche Verlauf der Fehlerhäufigkeit stellt die Lernkurve bzw. Lernrate des Systems dar. Sie ist nicht unbedingt proportional zur Anzahl der Lernschritte. Durch die schon erwähnten Loss-Funktionen wird dieser Prozess gesteuert.
Bei den meisten Netzen wird der schon 1986 erfundene sog. Backpropagation-Algorithmus angewendet. Der Fehler zwischen der tatsächlichen Ausgabe des Netzwerks und der erwarteten Ausgabe wird berechnet und verwendet, um die Gewichte so lange zu ändern, bis der Fehler klein genug geworden ist, also unter die vorgegebene Fehlergrenze gesunken ist. Der Algorithmus selber leitet zuerst die Eingabedaten durch das Netz, und berechnet die Ausgabe, dann durch Vergleich mit seinem Trainingsmuster den Fehler, befördert die vorläufige Ausgabe wieder rückwärts durch das Netz, passt dann die Gewichte für die Verbindungen an und wiederholt das Ganze bis zur gewünschten Genauigkeit. Es gibt viele unterschiedliche Methoden, wie dies im einzelnen passiert: klassisch mit konstanter Lernrate für das ganze System, resilient mit zeitabhängiger Lernratenanpassung für jedes einzelne Neuron, Momentum Term, einer Methode zum Ausbremsen von Lernstillständen und zur Vermeidung von Oszillationen, Flat Spot Elimination, Second Order Propagation, Weight Decay und Pruning, dem Entfernen nicht mehr lernender Neuronen.
Die Informationen über die Verbindungsstärken werden meist in den Datenbanken des Systems gespeichert und in der Regel in einer Cloud zur Verfügung gestellt. Sie repräsentieren sozusagen das „Wissen“ des Systems.
Die Fehlerbehandlung selber ist eine kleine Wissenschaft für sich. Manchmal führt kein Weg daran vorbei, das Netz mehrfach zu initiieren. Wenn nach einer solchen Prozedur die Fehlerrate gleich bleibt, hat man endlich Vertrauen in die Stabilität des Netzes.
Bei den Vorgaben für die Lernrate muss man höllisch aufpassen. Es kann passieren, dass nach einem schnellen Anfangserfolg des Trainings die Fehlerrate wieder steigt, bei kleiner Lernkurve auf einem konstantem Niveau beharrt, einen Minimalwert erreicht und dann bei Fortsetzung der Trainingsschritte wieder steigt, zwischen den Schichten des Netzes oszilliert oder gefundene gute Minima der Fehlerrate wieder verlassen werden.
Bei dem Training muss man darauf achten, wie man trainiert und vor allem, dass man nicht zu viel trainiert. Dann besteht die Gefahr, dass das Netz nur noch die Antworten auf seine Trainingsfragen auswendig lernt und nicht mehr viel für Aufgaben taugt, die außerhalb der Trainingsdatenmasse liegen. Man sagt dann, dass das Netz overfitted ist. Warum das so ist, lässt sich bis heute noch nicht zufriedenstellend erklären (das Netz, das „unbekannte Wesen“ als Forschungsobjekt). Es ist eine ziemliche Kunst, hier den richtigen Weg zu finden[12].
Das Training kann man entschieden mit Hilfe gelabelter Daten verbessern, d.h. man ordnet den Daten der Trainingsmenge sogenannte Tags zu, die bestimmte Attribute der Daten beschreiben, z.B. Schlagwörter für die Bedeutung eines Satzes oder für Tätigkeiten oder die Beschriftung von Bildern. Das kann manuell geschehen, also durch Menschen, die die Schlagwörter den Texten oder Bildern zuordnen. Diese Methode ist natürlich sehr aufwendig, aber am genauesten - und abhängig von der Qualifikation der „Tagger“. Alternativ oder ergänzend dazu ist die maschinelle Zuordnung, bei der Computerprogramme die Daten analysieren und eine Zuordnung vornehmen. Auch hier gibt es wieder sehr unterschiedliche Verfahren wie Entscheidungsbäume oder Wissensbasen, die Beziehungen von Begriffen und Ideen zu Dingen beschreiben.
Dem menschlichen Gehirn nachempfunden sind gepulste Neuronale Netze. Bei ihnen erzeugt die Aktivierungsfunktion der Neurone aus den Eingabesignalen statt eines einzelnen Impulses zeitlich begrenzte, schnell hinereinander erfolgende Impulse, sogenannte Spikes. Das Training solcher Netze soll weniger Rechnerleistung verbrauchen[13] als bei herkömmlichen Netzen und soll sich besser für die Verarbeitung von zeitabhängigen Ereignissen eignen.
Hersteller der bekannten Sprachbots wie ChatGPT oder Bard bzw. Gemini rühmen sich mit hunderten von Millionen Parametern, mit denen ihre Systeme arbeiten. Darunter werden (hauptsächlich) die Gewichte zwischen den Neuronen des Netzes verstanden. Das Llama-2-Chatmodell von Meta toppt dies sogar mit 70 Milliarden Parameter, ChatGTP 4.0 tut es nicht unter der Billionengrenze (1.76 Billionen). Dies verdeutlicht den immens hohen Aufwand, der hier getrieben wird. Parameter in den künsstlichen Neuronalen Netzen entsprechen also dem, was in unserem Gehirn die Synapsen sind. Davon haben wir, wenn wir gut auf uns aufgepasst haben, bis ins hohe Alter einige hundert Billionen. ChatGPT-4, das - Stand Ende 2023 - mächtigste Chatbot-System, hat davon gerade mal eine Billion. Die meisten Chatbots kommen mit rund 175 Milliarden solcher Parameter aus.
Ein Problem besteht im Aktuellhalten der Systeme. Wenn ein Neuronales Netz z.B. direkten Zugriff auf das Internet (oder Teile davon) hätte, würde sich die Datenmasse laufend ändern[14]. Mit nicht zu vernachlässigender Wahrscheinlichkeit betrifft dies auch Sachverhalte, die in den Trainingsdaten nicht oder nicht gut repräsentiert sind. Schon deshalb, aber auch wegen der laufenden Datensatzerweiterungen ist es erforderlich, die Systeme nachzutrainieren, damit sie lernen, wie sie neue und nicht gut verstandene alte Sachverhalte präziser und effektiver behandeln können. Wenn ein Modell korrekt arbeitet, sollte es in der Lage sein, vorauszusehen, was in den durch neue Daten repräsentierten Bereichen passiert.
Es ist oft die Rede von selbstlernenden Systemen, von denen es heißt, sie können sich ohne menschliches Eingreifen verbessern. Diese Aussage ist insofern irreführend, weil sich dieses „Selbstlernen“ nur auf die Trainingsdaten bezieht. Die Feedbacks zur Fehlerkorrektur werden in diesen Fällen meist nicht von Menschen gegeben, sondern von Algorithmen erzeugt. In der Regel handelt es sich um eine Kombination von menschlichem und maschinellem Feedback.
Entwicklungstrends
Das Aufeinandertreffen von Big Money mit Big Data hat den heute konstatierbaren Erfolg der KI-Systeme möglich gemacht. Der Schrei nach immer größeren Trainingsdatenmengen verspricht allerdings keine Verbesserung. Im Gegenteil, hartnäckig hält sich das Gerücht, dass die Chatbots sich seit dem Frühjahr 2023 eher verschlechtert haben, so eine Studie der Stanford University vom August 2023[15].
API-Angebote: Eine kaum überschaubare Zahl neuer Anwendungen befindet sich in der Pipeline, überwiegend industrielle Entwicklungen, die auf den von den großen Anbietern zur Verfügung gestellten Plattformen aufbauen. OpenAI, Google, Meta und viele andere bieten ihre Large Language Models über Schnittstellen, sogenannte Application Programming Interfaces (APIs) für spezielle Weiterentwicklungen an. Die Partner können dann das universelle Sprachmodell nutzen und mit von ihnen bestimmten Datenbeständen ergänzen, z. B. mit Produkt- oder Kundeninformationen. Die Modelle lassen sich durch zusätzliche Neuronenschichten erweitern und mit den neuen Datenbeständen trainieren. Folgt man den best practice-Vorschlägen der Anbieter, so kann man sich beachtliche Mühen bei der Auswahl des richtigen Trainingsverfahrens ersparen, so behaupten jedenfalls die Anbieter. Man darf gespannt sein, wie die Anwenderwelt in wenigen Jahren aussehen wird, ob die augenblickliche Begeisterung anhält oder - wie oft bei gehypten Neuerungen üblich - realitätsgetriebener Enttäuschung Platz macht.
Neuromorphe Systeme: Fieberhaft wird daran gearbeitet, eine neue KI-Generation mit maschineller Wahrnehmung zu entwickeln[16]. Das Defizit heutiger Computer, nicht zu eigenständiger Wahrnehmung fähig zu sein, ist eines der Haupthindernisse z.B. beim Autonomen Fahren. Nach heutigem Stand der Technik werden sich die autonom fahrenden Autos nie auf Feldwegen zurechtfinden.
Heutige Computer benötigen immer ein Modell der Außenwelt, eine Simulation, die berechnet werden muss. Die Hoffnung der Entwickler für eine Künstliche Intelligenz mit maschineller Wahrnehmung sehen die Zukunft in einer Sackgasse, solange bewusstseinsbehaftete Vorgänge wie Wahrnehmung nur in Software abgebildet werden können, also Computer nichts selber Erkanntes aufnehmen können, sondern alles als digitalisierten Input verabreicht bekommen müssen. Deshalb konzentrieren sich Entwickler darauf, Systeme zu erfinden, die nicht nur in Software realisierte Modelle verarbeiten, sondern auch kognitive Aufgaben hardwarebasiert erledigen können, in Anlehnung an die uns bekannten Vorgänge im menschlichen Gehirn. So sollen die softwaretechnisch simulierten Neurone durch Lösungen ersetzt werden, die in Hardware realisierte Leistungen erbringen, mit Spulen, Kondensatoren, Transistoren und Dioden - Physik statt Mathematik, Hardware statt Software, sogenannte Memristoren.

Memristor
Sie sollen - gewissermaßen als Nachbau der Synapsenleistungen - spannungsgesteuert Wiederstände herstellen können, die nach dem Stromfluss erhalten bleiben und schnell aus- und rückgebildet werden können, in Anlehnung an das Arbeits-, Kurz- und Langzeitgedächtnis, über das unser Gehirn verfügt. Gelingt dies, so wird man einen entscheidenden Schritt weiter sein. Denn das Gehirn rechnet nicht, das Gedächtnis ist, wie wir vermuten, in den Synapsen codiert, also im Vergleich mit den heutigen Computern in der Hardware. Das Ergebnis sind dann sogenannte neuromorphe Systeme. Künstliche Nervenzellen, sogenannte Long Short-Term Memory-Bausteine sollen über eine Art langes Kurzzeitgedächtnis verfügen, sich an frühere Erfahrungen „erinnern“ und sie auch wieder „vergessen“ können. So ließen sich auch nicht mehr benötigte Informationen aus dem System löschen. Professor Otte von der Universität Ulm gehört zu den Optimisten und erwartet Ende des Jahrzehnts vorzeigbare erste Erfolge.
Biologische Computerplattformen: Australische Forscher[17] haben bereits einen halbbiologischen Computerchip entwickelt, für den sie gängige siliziumbasierte Schaltkreise mit gezüchteten menschlichen Gehirnzellen kombiniert haben. Man verspricht sich davon, die Bereiche der künstlichen Intelligenz und der synthetischen Biologie zu verbinden, um programmierbare biologische Computerplattformen zu schaffen. Dieses Unterfangen wirft allerdings neue Schwierigkeiten auf, weil die organischen Einheiten für ihren Energieverbrauch „versorgt“ werden müssen. Ein erstes so geschaffenes Produkt soll bereits Ping Pong spielen können.
Mensch-Computer-Schnittstellen: Auf vielen Gebieten wird daran geforscht, wie Menschen direkt mit Computern verbunden werden können, bisher nur in die Richtung, dass Maschinen über Nerven geleitete Impulse aufnehmen und verarbeiten, z.B. die Greifbewegungen einer künstlichen Hand. Davon sind Teile der Robotik betroffen. Neuroadaptive Technologien könnten den Menschen auch eine Art sechsten Sinn verleihen, also uns etwas wahrnehmen lassen, wofür wir keine Sinnesorgane haben (z.B. Radioaktivität). Dabei können auch sogenannte Wearables eine Rolle spielen, die auf unauffällige Weise eine Vielfalt von Daten sammeln können.
Viele dieser Entwicklungen lassen sich unter dem Begriff Transhumanismus zusammenfassen. Damit ist im Gegensatz zum Posthumanismus die Auffassung gemeint, dass Menschen ihre natürlichen Grenzen durch Technik erweitern können. Künstliche Intelligenz spielt dabei in Verbindung mit Nano- und Gentechnik eine Rolle. Diese Denkrichtung ist zu unterscheiden vom Posthumanismus, deren Vertreter glauben, durch die Verschmelzung von Mensch und Technik neuartige Wesen schaffen zu können.
Leistungsgrenzen
Wir haben heute nicht wirklich Ahnung, wie unser Gehirn funktioniert, das in so kurzer Zeit und ohne erkennbare Mühe so schnell etwas wiederekennen und ein Gesamtbild aus lauter Einzelteilen herstellen kann. Von diesem Leistungsniveau sind die Neuronalen Netze noch weit entfernt. Hier einige wichtige Defizite:
Intelligenz ohne autonome Wahrnehmung und Bewusstsein: Computer haben keine eigene Wahrnehmung, kein Bewusstsein und keine Gefühle. Sie „verstehen“ nicht, womit sie beschäftigt werden. Ihnen muss die Welt (oder Teile davon) in Form von Matrizen dargestellt werden, die aus Zahlen bestehen, Nullen und Einsen. Sie kennen nur das Modell, nicht die hinter dem Modell steckende Semantik. Die Welt wird ihnen als softwaretechnisch erzeugtes Modell der Welt repräsentiert. Deshalb sind die Phantasien von einer Superintelligenz, die die Menschheit beherrschen oder gar vernichten kann, auf der Basis heute baubarer Computer (einschließlich Quantencomputer )[18] nur Phantasien. Wenn die Welt von KI-Systemen beherrscht wird, dann nur, wenn Menschen sie dafür benutzen. Aus eigenem Antrieb sind sie dazu nicht fähig. Wenn Sam Altman oder Elon Musk vor dieser Gefahr warnen, kann man dies getrost in die Schublade bemühten Marketings einordnen, um nochmals einen Schub Aufmerksamkeit zu erhalten.
Wie assoziatives Denken im Gehirn, das oft in Zusammenhang mit kreativem Denken gebracht wird, wirklich funktioniert, ist noch weitgehend unbekannt. In Daten vorkommende Muster, die von einer KI-Anwendung entdeckt wurden, aber bisher noch kein Mensch gefunden hat, werden dann als besondere assoziative Leistungen, manchmal sogar als Kreativität bezeichnet.
Die gut formulierten von den KI-Chatbots produzierten Texte dürfen nicht darüber hinwegtäuschen, dass sie nur Ergebnisse von Statistik und Wahrscheinlichkeitsrechnung sind, erst möglich geworden durch früher unvorstellbar große Datenmengen und superschnelle Prozessoren. Die Gefahr besteht darin, dass die Ergebnisse für Aussagen kluger Menschen gehalten werden und nicht für Wiederholungen und Kombinationen von in den unendlich erscheinenden Datenmengen gefundenen Mustern.
Trainingsdaten: Wir haben bereits angesprochen, dass die Auswahl der Daten für Test und Training die Grundlage der Leistungsfähigkeit des betroffenen KI-Systems ist. Die Trainingsdatenmasse muss nicht nur sehr groß, sondern auch für das spätere Aufgabengebiet repräsentativ sein. Nach bisherigen Erfahrungen kann man davon ausgehen, dass die Leistungen eines solchen Systems zufriedenstellend bleiben, solange die Anforderungen an das System Sachverhalte betreffen, die in den Trauningsdaten gut repräsentiert sind.
Die Systeme sind allerdings nicht gut in der Erkennung der Grenzen ihrer Leistungsfähigkeit. Mit der Entfernung der zu interpretierenden Daten von der Trainingsstichprobe wächst dieses Problem. Wenn die Systeme sich im Bereich der Extrapolation aus der ursprünglichen Domain befinden, tun sie etwas, das verniedlichend als Halluzinieren beschrieben wird. Die durch Wahrscheinlichkeitsrechnung getriebene Suche greift ins Leere und fängt an, zu fantasieren und eigentlich weniger wahrscheinliche Ergebnisse mangels Vergleich als hochwahrscheinlich darzustellen. In Aussagesätze verpackt verleiht dies dem Ergebnis den Eindruck von Objektivität. Menschen, die diese technischen Hintergründe nicht kennen, vertrauen den Aussagen und stellen keine kritischen Fragen mehr. Dies kann schwerwiegende Folgen haben. Etwas drastischer ausgedrückt: KI produziert buchstäblich Schwachsinn - sie erfindet auf der Grundlage von Trainingsdaten Dinge, die gut klingen.[19]
BIAS: Eventuelle Verzerrungen in den Trainingsdaten werden auch die Ergebnisse für die Aufgabenstellungen bei Daten außerhalb der Trainings-Domain verzerren, bekannt als sogenanntes BIAS-Problem. Fei-Fei Li[20], eine ehemalige Google-KI-Chefentwicklerin hat dies gut auf den Punkt gebracht:
Wenn vor allem weiße amerikanische Jungs in Kapuzenpullis Maschinen entwerfen und die Zukunft programmieren, ticken die Maschinen auch wie weiße amerikanische Jungs in Kapuzenpullis, nur die Welt besteht nicht nur aus weißen amerikanischen Jungs in Kapuzenpullis.
Das System hat also Vorurteile. Bekannt dafür sind die von (vermutlich nicht nur) amerikanischen Gerichten benutzten predictive analytics-Systeme zur Vorhersage der Resozialisierungschance, bei der Menschen mit dunkler Hautfarbe chronisch benachteiligt werden. Gleiches dürfte für die Benachteiligung von Frauen gegenüber Männern gelten. Wenn Häufigkeit das Maß für Bedeutung und Wichtigkeit ist, kann die Verzerrung zu Gunsten der Häufigkeit viele Lebensbereiche betreffen.
Bisher von den großen Sprachmodellen verwendete Trainingsdaten haben alle gemeinsam:
- Nur digitalisierte Information wird erfasst. Der große (zurzeit) nicht digitalisierbare Rest menschlicher Erkenntnisse bleibt ausgeschlossen.
- Gedruckte und digitalisierte Texte werden noch für lange Zeit überproportional von weißen Männern verfasst sein.
- Trotz vieler Randkorrekturen wird das dem Aufmersamkeitsalgorithmus der Transformermodelle innewohnende Dogma Wichtigkeit = Häufigkeit zu Verzerrungen in der Priorität dessen führen, was gefunden wird.
Bewertung der Trainingsergebnisse: In bestimmten Trainigsphasen müssen für viele KI-Systeme die von ihnen erzeugten Antworten bewertet werden. Gleiches gilt für Fragestellungen und Antworten, die als problematisch gemeldet werden. Diese Arbeit wird oft von schlecht bezahlten und auch nicht besonders qualifizierten Menschen durchgeführt und hat Einfluss auf das Verhalten des trainierten Systems. Welche Ergebnisverzerrung dadurch bewirkt wird, wurde bisher nicht untersucht und ist daher weitgehend unbekannt.
Mangelnde Transparenz: Regelgetriebene Expertensysteme können das Zustandekommen ihrer Ergebnisse gut und nachvollziehbar erklären. Bei Neuronalen Netzen ist dies prinzipiell nicht möglich. Die hidden layers der Systeme sind eine Art Black Box. Forderungen nach Transparenz greifen ins Leere. Einige Anbieter versuchen, diesen Mangel wenigstens dadurch abzumildern, indem sie Scorecards zur Offenlegung der Kriterien für die Auswahl der Trainings- und Testdaten anbieten.
Ganz problematisch wird die Situation, wenn die laufende Nutzung des Systems in die Trainingsdatenbasis einbezogen wird. Hier macht sich der nicht zu toppende Grundsatz garbage in - garbage out in ziemlich korrekturresistenter Form bemerkbar. Eine Filterung der Benutzereingaben führt eher zu neuen Problemen als zur Abhilfe. Wird aber auf solches Trainigsmaterial verzichtet, so lernt das System auch wenig über sich verändernde Benutzergewohnheiten.
Simulation von Gefühlen: Unser Gehirn hat sich hauptsächlich durch soziale Interaktion entwickelt. Der Technik der Neuronalen Netze steht dieser Weg nicht zur Verfügung. Sie ist auf Training angewiesen und muss sich den emotional touch auf andere Weise beschaffen, durch Dinge, die man in Zahlen repräsentieren, also messen kann. Dazu dient u.a. die Sentimentanalyse. Beschleunigter Herzschlag ist z.B. messbar, aber nicht die Ursache für großes Glückgefühl (oder bescheidener: für Aufregung), sondern gehört zu den Folgen. Diese erst haben den Vorteil, messbar zu sein. Und genau diesen Weg gehen viele Systeme, um ihrer Datenbasis emotionale Konnotationen zuzuordnen. So hat schon Microsoft Viva seine Benutzerinnen und Benutzer aufgefordert, zu bewerten, was sie gerade tun, z.B. durch Anklicken eines Symbols aus einer Liste von Smilies:

Dann kann man dem Geschehen emotionale Zustandswerte zuordnen. Diese kann man in die Trainings-Domain für die Weiterentwicklung des Systems aufnehmen, in der Hoffnung, dass das System in Zukunft dann auch einen Hauch von Emotionalität an den Tag legt. Die Realität wird durch ihre Simulation ersetzt und unterliegt dem Auswahl-Bias, wer gerade sich bemüßigt gefühlt hat, einer solchen Bewertungsaufforderung zu folgen.
Großer Ressourcenverbrauch: Die Leistungen eines aktiven Gehirns mit seiner Kapazität von ca. 10 Zettaflops schätzt man auf 15-23 Watt[21] abhängig vom Alter. Google gibt an, dass eine einfache Bard-Anfrage serverseitig ca. 100 mJ (Millijoule) verbraucht. Hochzurechnen, welche Energie die riesigen Serverfarmen verbrauchen, führt warscheinlich schon zu einem in einem Monat überholten Ergebnis, einschließlich der Umrechnung in den Öko-Footprint[22] . Die Serverleistungen der Plattformanbieter Google, Amazon und Facebook allein werden mit 200 Milliarden KWh pro Jahr angegeben[23] und machen damit schon über 10 Prozent des gesamten jährlichen Stromverbrauchs von Computen aus, wird jedenfalls im Jahr 2023 angenommen. Google Bard sagt, das entspricht dem Jahresverbrauch eines Landes wie Portugal. Jetzt darf man Annahmen über die jährlichen Steigerungsraten machen, vermutlich im zweistelligen Bereich[24].
Machtzuwachs der großenTech-Konzerne: Der riesige Ressourcenaufwand insbesondere auch für das Aktuellhalten der Datenbasis wird die Vormachtstellung der großen Konzerne weiter stabilisieren. Apple, selbst Mitglied dieses erlauchten Kreises, scheint erkannt zu haben, diesen Wettlauf nicht mehr auf Augenhöhe mithalten zu können und hat sein Large Language Model Ferret als Open-Source-Code zur Verfügung gestellt[25], in der Hoffnung, dass die OpenSource-Community die Entwicklung vorantreiben wird. Dahinter steckt die bittere Erkenntnis, dass es einer enormen Infrastruktur bedarf, um ein großes Sprachmodell zu betreiben. Man muss also entweder selber ein mächtiger Hyperscaler sein oder mit einem solchen kooperieren. Wenn sich die Großen zusammentun, so hat das weitere Konsequenzen auf den Einfluss der Tech-Konzerne mit der von ihnen verbreiteten amerikanischen Sicht, der die Europäer nichts oder wenig entgegensetzen. Ganz zu schweigen von der fast vollständigen Ausblendung der asiatischen Welt und den Folgen des von der aktuellen Politik vorangetriebenen Blockdenkens. Sicher gehört Optimismus dazu, in der als globale Partnerschaft angekündigten Kooperation des Axel Springer Verlags mit OpenAI eine Korrektur drohender Verflachung zu sehen. Gemäß diesem Deal stellt Springer die digitalisierten Inhalte seiner Medien - offensichtlich einschließlich der Bild-Zeitung - OpenAI zu Trainingszwecken zur Verfügung und erhält im Gegenzug als qualitätsjournalistisch klassifizierte Zusammenfassungen dieses Daten-Konglomerats[26]. Der Axel-Springer-Verlag als neuer Juror für Qualitätsjournalismus? Nur noch zu toppen, wenn man den terabyte-schweren Tagesausstoß der Social Media-Posts auch noch den Trainingsdaten einverleibt. Querdenkern jedenfalls droht die Vertreibung aus dem digitalen Paradies.
KI-Anwendungen
Es gibt kaum noch größere Softwaresysteme, in denen KI-Elemente keine Anwendung finden und zunehmend weniger Lebensbereiche, die davon unberührt bleiben. Für den Durchbruch in der Öffentlichkeit hat längst ChatGPT gesorgt. Alle diese Produkte beruhen auf den Large Language Models. Sie werden in immer mehr Unternehmenssoftware eingebaut.
ChatBots
Schon 2017 hatte Google sein Transformer-Modell veröffentlicht, die Grundlage für die meisten ChatBots. Google hat aber auf die Veröffentlichung einer darauf beruhenden Software verzichtet. Glaubt man Google, war das Motiv für diesen Verzicht die noch für zu hoch empfundene Unzuverlässigkeit der Ergebnisse. Irgendwo müssen die Jungs dann in Tiefschlaf versunken sein, denn von den Folgen der Microsoft-Entscheidung, das Produkt von OpenAI mit mindestens 10 Milliarden Dollar zu fördern, wurden sie gründlich überrascht. Hier geht es ums Geschäft: Google macht seinen Umsatz zu geschätzt 95 Prozent mit Werbung, Microsoft bisher nur mit sicher unter fünf Prozent. Die personalisierte Werbung, die sich bei einer Chat-Anfrage unterbringen lässt, ist nur ein Bruchteil von dem, was man neben den von einer Suchmaschine gefundenen Ergebnissen unterbringen kann. Darüber hinaus ist Microsoft der Coup gelungen, den Markt zu besetzen. Google hat sechs Monate gebraucht, um nachzuziehen, das obwohl sie die eigentlichen Vorreiter der Technik waren. In Veröffentlichungen einschließlich der Fachliteratur ist fast immer nur die Rede von ChatGPT.
ChatGPT, seit November 2022 auf dem Markt, ist - Stand Dezember 2023 - noch kostenfrei, beruht auf dem nicht mehr neuesten Sprachmodell (GPT-3) und hat keinen direkten Zugriff auf das Internet, sondern nur auf ein begrenztes Datenvolumen, das nichts weiß, was nach September 2021 passiert ist. Eine kostenpflichtige Version (für private Nutzer für 20 Dollar/Monat) weist diese Mängel nicht mehr auf und benutzt das neuere Sprachmodell GPT-4. Microsoft hat den Chatbot in seine Suchmaschine Bing eingebaut; Voraussetzung für die Nutzung ist nur ein Microsoft-Konto.
OpenAI hat nun eine Business-Version angekündigt. Viele Firmen waren skeptisch bezüglich des Einsatzes, weil sie befürchteten, dass die firmeninterne Konversation mit dem System in das Trainingsmaterial für künftige Aktualisierungen eingeht und damit die Gefahr bestünde, dass Firmeninterna, vielleicht sogar Geschäftsgeheimnisse das Unternehmen verlassen. Nun wird zugesichert, in Zukunft Daten aus der firmeninternen Nutzungen nicht zu Trainingszwecken zu verwenden. Dies gilt jedoch nur für die Bezahlversion von ChatGPT, Stand Dezember 2023. Googles Chatbot Bard (ab Februar 2024 umbenannt in Gemini) weist seine Benutzer ausdrücklich darauf hin, dass dies nicht gilt; beim ersten Aufruf heißt es: "Zur Qualitätssicherung können Prüfer deine Unterhaltungen mit Bard verarbeiten. Gib also bitte keine vertraulichen Daten ein".
Der Glaube an den verkündeten Schutz vor dem Gebauch interner und privater Daten zu Trainingszwecken fällt jedoch immer noch vielen Kunden schwer, denn die Daten liegen auf den Servern des Anbieters. Die Kritik vieler Firmen an der mangelhaften Transparenz ist ein wesentlicher Grund für die noch zögerliche Anwendung.
Dann ist noch die Flut der wie Phönix aus der Asche entstandenen vielen alternativen Chatbots zu nennen, hier einige Beispiele:
- FreedomGPT verzichtet nach eigenen Angaben auf Filter und Wortzensuren, die in ChatGPT eingebaut sind, ist derzeit allerdings nur in wenigen Sprachen verfügbar und nur sehr begrenzt kostenfrei.
- WormGPT und FraudGPT sind die bad boys und bieten sich für die Erzeugung von Schadsoftware an.
- DeppGPT[27] nimmt die Abfragerei auf die witzige Schulter und liefert andere Halluzinationen als die „anständigen“ Chatbots.
OpenAI hatte bis zu GPT-3 sein Sprachmodell offen gelegt, schon bei GPT-3.5 und jetzt bei Nr. 4 ist dies nicht mehr der Fall.
Viele Firmen warten mit ihren eigenen Chatbots für den internen Gebrauch auf: Mercedes und Siemens mit ChatGPT, Bosch mit eigenem BoschGPT, Merck mit einer eigenen Version MyGPT@Merck, der Drogeriemarkt dm ebenfalls mit einem eigenen Chatbot. Wenn man länger recherchiert, findet man bestimmt noch ein paar Dutzend weiterer Firmen. Der Trend zeigt ungebremste Fortsetzungslaune.
Mehr als 150 Start-Ups allein in Kalifornien sind dabei, KI in Geschäftsmodelle zu integrieren. Nettes Beispiel: einen Strafzettel fotografieren, und ein KI-System erstellt ein darauf abgestimmtes Widerspruchsschreiben. Alle Anbieter arbeiten mit Hochdruck an der Weiterentwicklung ihrer Produkte. Die Chatbots sollen neben der Texteingabe auch eine Kommunikation in gesprochener Sprache akzeptieren und ihre Ergebnisse ebenfalls per Sprache mitteilen können. Die Stimme selbst basiert dabei auf einem wenige Sekunden langen gesprochenen Beispieltext. Die Bots werden Bilder analysieren, mathematische Berechnungen oder Diagramme erstellen können, alles bereits im Herbst 2023 angekündigt. Der nächste Schritt soll dann darin bestehen, aus den gefundenen Ergebnissen oder vorgenommenen Bewertungen auch Handlungen abzuleiten, zunächsst nur vorschlagsweise, dann aber auch als direkte Aktion, z.B. Termine vereinbaren,Telefonate durchzuführen oder eine Mail zu verschicken. Noch darf es die Phantasie der Nutzer beschäftigen, was eine sogenannte event-driven architecture durch bessere Verbindungen zwischen verschiedenen Anwendungen - mit oder ohne Künstlicher Intelligenz - für neue Chancen vor allem im B2B- und B2C-Bereich[28] eröffnen wird.
Spezielle Programme
Spezialisierte Funktionalitäten bieten z.B. Scribe mit Arbeitsanleitungen für das, was man gerade am Bildschrirm tut, als Training für andere Nutzer. Midjourney kann Eye-Catching-Bilder aus Texteingaben erzeugen. Leiapix kann 2D-Bilder in 3D-Ansichten umwandeln. Murf kann Text in mit verschiedenen menschlichen Stimmen gesprochene Sprache umwandeln. Stocking kann Logos erzeugen. Es existieren jede Menge weitere Spezialisten wie Runwayml für Videos und Filme, CodeFormer für Restaurierungsarbeiten an Fotos. ZMO.ai erlaubt es, ein eigenes Foro hochzuladen, Kleidungsstücke virtuell auszuprobieren und verspricht OnlineShop-Betreibern die Einsparung von Rücksendekosten. Luminous von dem deutschen Start-Up Aleph Alpha kann nach eigener Aussage mit Sprache besonders zuverlässig umgehen und Bild und Text kombinieren, z.B um das auf Fotos Dargestellte zu beschreiben. Sicher gibt es noch Dutzende erwähnenswerter anderer Anwendungen. Keine Gewähr, dass die obigen Beschreibungen noch stimmen, die Infos habe ich aus älteren, immerhin noch aus dem Jahr 2023 stammenden Publikationen entnommen.
Large Language Models
Mehrere Large Language Models werden heute angeboten. Die wichtigsten sind das bereits erwähnte, in dem kostenlosen ChatGPT verwendete GPT-3, ebenfalls GPT-J, beide von OpenAI, PaLM 2, TuringLLG und das spezielle Modell für Bard von Google, viele davon open source-Produkte.
Nicht öffentlich angeboten wird GPT-4 von OpenAI, das in dem Bezahl-ChatGPT sowie als Basis in den Microsoft-Produkten verwendet wird und ein sehr mächtiges System ist, ebenso LaMDA von IBM und Llama-2 von Meta, beide auch für die firmeneigenen Produkte eingesetzt.
Llama-2 gibt es in unterschiedlichen Größen von 7 bis 70 Milliarden sogenannter Parameter, in über 100 Sprachen, die Variante OpenLlama ist open source.
Nach Auskunft einer Bard-Abfrage arbeitet GPT-3.0 mit über 175 Milliarden, GPT 3.5 schon mit 1.5 Billionen und GPT-4.0 mit 176 Billion Parametern, also dem fast Tausendfachen von GPT-3, sicher ein wichtiges Argument für die Kostenpflichtigkeit der mit diesem Modell arbeitenden Services. Während GPT-3 noch unter open-source-Bedingungen offengelegt war, bleiben die Algorithmen und Filter von GPT-3.5 und GPT-4 als Geschäftsgeheimnisse unveröffentlicht.
Daneben gibt es mehrere kleinere LLMs, die größtenteils nicht öffentlich sind, z.B. Nividia mit Megaton-Turing LNG für angeblich besonders realistische Texte und DeepL-LLM des Übersetzungsdienstes DeepL mit „nur“ 137 Milliarden Parametern. Weiter sind zu nennen RedPajama, Databricks Dolly 2.0, MosaicML MTP-30B und MTP-7B Story Writer, TII Falcon 40B, alle open sorce, oft nur in wenigen Sprachen, aber immer in englisch und die proprietäten Systeme Aleph Alpha Luminous und Anthropic Claude 2.
Deep Learning-Systeme sind Neuronale Netze mit mehr als üblich vielen Neuroneschichten, werden mit besonders großen Datenmengen trainiert und haben kompliziertere Verbindungen zwischen den Neuronen (z.B. infolge nichtlinearer Aktivierungsfunktionen).
Seltsamerweise gelten die mit weniger Parametern trainierte Systeme oft als qualitativ besser als die ganz großen Systeme. Das „Eigenleben“ der Neuronalen Netze präsentiert sich schon als Forschungsthema. Viele der genannten Systeme lassen sich mit firmeneigenen Daten kombinieren und dann speziell mit solchen Daten trainieren, wovon man sich eine verbesserte Genauigkeit und Nützlichkeit verspricht.
Es sei nochmals ausdrücklich erwähnt, dass der Betrieb von Systemen solcher Mächtigkeit nur dank Big Data und der heute verfügbaren superschnellen Grafikprozessoren möglich ist.
KI-Einbau in Unternehmenssoftware
Neuronale Netze auf der Basis von Large Language Models werden in immer mehr Standardprogramme der großen Unternehmen für Firmenstandardsoftware eingebaut.
- Salesforce nennt sein feature Einstein Copilot[29] und vermarktet es als Assistenzsystem für Prognosen, Scoring für predictive leads sowie Personalisierung von Angeboten und Vorschlägen für Service-Antworten. Salesforce will es in jede seiner Anwendungen integrieren. Für die sagenhafte Summe von 28 Milliarden Dollar hatte Salesforce bereits Ende 2021 das Chat-Programm Slack gekauft und will das Tool nun zum künstlich-intelligenten Dreh- und Angelpunkt seiner kompletten Anwendungen machen. Die Tools sollen die Produktivität steigern, indem sie den Benutzern auch Fragen stellen und relevante Antworten auf der Grundlage von unternehmenseigenen Daten aus der Salesforce Data Cloud erhalten sollen, sagt die Firma. Mit Einstein Copilot Studio können sich die Firmen auch ihre eigenen kleinen KI-Anwendungen basteln, folgt man der Salesforce-Werbung.
- SAP ist auch nicht untätig und punktet mit der Erzeugung von Leads für ansprechbare Kunden, Chatbots für die Beantwortung von Kundenanfragen, Gestaltung von Marketing-Kampagnen, predictive analytics für Trenderkennungen, Computer Vision für Bildinterpretation beispielsweise bei Produktinspektionen und Fraud Detection zur besseren Erkennung von Betrugsmanövern. SAP arbeitet mit einem eigenen Large Language Model namens SAP Conversational AI [30] und ist dabei, in einer Cloud Platform for Artificial Intelligence diese und weitere Leistungen seiner Kundschaft anzubieten (CAI).
- Die Aufzählung kann man nun fortsetzen mit SAP-Konkurrent Oracle mit KI-Elementen für Kundenservice, Sales und Marketing, ebenfalls als Cloud-Lösungen angeboten oder
- Workday für eine noch recht bescheidene Workday Virtual Assistent (VA) genannte Funktion für die Beantwortung von Kundenfragen und der Vereinfachung interner Prozesse wie Berichte erstellen. Man riskiert nicht viel mit einer Wette, dass alle Anbieter von Firmensoftware auf diesen Zug aufspringen und ihre Softwareangebote entsprechend aufpimpern.
Einsatzbereiche
So wundert es denn nicht, dass kein gesellschaftlicher Bereich von explosionsartig wachsenden Anwendungsangeboten verschont bleiben wird; hier nur eine kurze Auflistung:
- Gesundheitswesen: bessere Diagnosen z.B. durch Mustererkennung in Röntgenaufnahmen, personalisierte Therapiepläne, Integration von tragbaren Geräten mit der Sammlung einer Unzahl von persönlichen Daten und Erzeugung von Warnungen und Vorschlägen für die eifrigen Träger dieser wearables.
- Bildung: Die Corona-Krise hat gezeigt, was der rückständige Umgang mit Digitalisierung nicht zustande gebracht hat. Nun sollen Datenanalyse-Systeme die Leistung von Schülern vorhersagen können, damit Lehrer und Ausbilder frühzeitig eingreifen können. KI-gesteuerte Werkzeuge zur Sprachübersetzung und Echtzeit-Transkriptionsdienste sollen Sprachbarrieren abbauen, um unterprivilegierten Menschen sowie Menschen in abgelegenen Gebieten bessere Chancen zu bieten. Man darf gespannt sein, was die Ankündigungen bringen. Die sozialen Folgen der Fokussierung auf das Digitale scheinen keiner besonderen Beachtung zu bedürfen.
- Kundenbetreuung egal wo, für Call- und Service Center oder Einzelhandel: Reaktion auf Kundenemotionen durch Integration von Stimmungsanalyse, Analyse des Käuferverhaltens, Vorschläge auf der Basis von entdeckten Vorlieben, Antizipierung der Kundenwünsche, Angebote sofortiger Hilfestellung im Gespräch für Service Center-Agents, automatische Durchführung bestimmter Aufgaben, vor allem in der Dokumentation. Es gibt sogar Angebote für einen Mobilen Kundenservice mit KI-gestützten Chatbots.
- Kunst: Die Irritationen durch von KI-Programmen erzeugte Bilder haben bereits Schlagzeilen gemacht. Juristen beschäftigen sich mit neuen Problemen für das Urheberrecht und die Verwertungsrechte von durch KI veränderten Originalen. Prophezeit wird, dass es nur noch wenige Monate dauern werde, bis ganze Sequenzen für Kinofilme auf der Grundlage von Eingaben zur Handlung und gewünschten Stimmung entwickelt werden können.
- Den Banken wenden schon seit längerer Zeit KI-Programme zur Überprüfung von Banktransaktionen und Compliance-Regeln und zur Vermögensverwaltung an.
- Produktion: Sehr spezifische Anwendungen für Produktionssteuerung, Qualitätskontrolle, predictive maintenance, Lieferkettenoptimierung und Robotik gibt es schön seit längerer Zeit; sie erfahren jetzt eine kräftige Boosterung.
- Informatik: Schon für die Chatbots wurde dafür geworben, dass man sie auch Computerprogramme schreiben, sie mit textlichen Anweisungen Code erstellen, debuggen oder vorhandenen Code erklären lassen kann. Etwas professioneller als die Chatbots besorgen das allerdings besondere Programme wie z.B. Github Copilot. Mit den Konzepten von LowCode und NoCode sind wir bereits auf die absinkende Qualität von Software vorbereitet. Nun bleibt zu hoffen, dass diese Entwicklung nicht einen weiteren Schub erhält.
- Landwirtschaft: Nutzpflanzen Wasserverbrauch überwachen, Erträge vorhersagen, Steuerung von selbstfahrenden Fahrzeugen, alles adressiert an Großunternehmen.
- Personalwesen: kombiniert mit Workflows Beschleunigung des Einstellungsprozesses, Erstellung von Stellenbeschreibungen, Überprüfung von Einstellungsunterlagen. In die Kritik geraten sind von einem KI-Unternehmen[31] angebotene Anwendungen, die Videos von Bewerberinnen und Bewerbern anhand von deren Mimik, Körpersprache und Sprechverhalten analysieren und auswerten können.
- Umwelt: gängige Themen sind Klimamodellierung, Überwachung der Umweltverschmutzung, Schutz von Wildtieren, Vorhersage von Naturkatastrophen
- Wie nicht anders zu erwarten, selbst die Militäreinsätze verändern sich durch KI. Die US-Streitkräfte führten kürzlich ihre bislang größte Übung unter dem Einsatz von KI-Technologie durch. "Wir wollen Daten, Analysen und KI in gemeinsame Arbeitsabläufe integrieren, von Abschreckung bis hin zu Angriffsmanövern" , erklärte Craig Martell, Chief Digital and Artificial Intelligence Officer im US-Verteidigungsministerium.
Die Aufzählung lässt sich sowohl ellenlang detaillieren als auch für andere Themenfelder fortsetzen. Das Fernziel von Sam Altman und seinem Team bei OpenAI allerdings ist die Schaffung einer „Künstlichen Allgemeinen Intelligenz“ (Artificial General Intelligence), also eines Systems, das in der Lage ist, jede Aufgabe zu lernen und auszuführen. Da sind wir nicht – noch nicht, sagt Altman im August 2023.
Ein genauerer Blick wollen wir auf die Büroanwendungen werfen. Schon seit geraumer Zeit hat uns Microsoft mit seinem M365-Paket (vormals Office 365) eine enorme Ausweitung digitaler Unterstützung beschert. Was vormals Textverarbeitung, Tabellenkalkulation und fürs Management Präsentationssoftware leisteten, ist schon längst durch Dutzende zusätzlicher Programme ergänzt und in die Cloud gehievt worden, bis hin zu Anreicherungen um Analyseprogramme zur Produktivitätsmessung, die sich bei genauerem Hinsehen als Monitoring und Reporting erweisen, wie ausführlich die Microsoft-Tools genutzt wurden. Zurzeit ist alles im Umbruch, und man kann nur schwer abschätzen, wie die Programme umorganisiert werden und was die massiv vorangetriebene KI-Aufrüstung Neues zu Tage bringen wird. Das gesprochene Wort in Videokonferenzen kann schon jetzt transkribiert werden. Bald wird die ChatGPT-Integration dafür sorgen, das die Inhalte kompletter Konferenzen textlich zusammengefasst werden können.
Microsoft Copilot soll diese Leistungen auf eine neue Stufe heben: Verbesserte Hilfen bei der Erstellung von Texten, Präsentationen, Mails, Erstellung von Zusammenfassungen oder Präsentationen von Texten, automatische Übersetzungen von alledem in andere Sprachen, kontextsensitive Angebote von Informationen zu der laufenden Arbeit auf der Basis der genauen Beobachtung dieser Arbeit und der Speicherung in Microsofts Graph-Hintergrundsystem. Weiter soll Copilot die Benutzer beim gemeinsamen Basteln von Dokumenten helfen und bei der Erstellung neuer Ideen und Konzepte unterstützen. Ob das solcherart betriebene individuelle Brainstorming dann noch den Namensteil „brain“ verdient, sei dahingestellt. Und nicht zuletzt: repetitive Arbeiten können automatisiert werden, d.h. sie fallen weg, was als Einsparung von Zeit und Mühe und Gewinnung dieser Zeit für „kreative Aufgaben“ dargestellt wird.
ERP-Systeme: Vermutlich alle großen Systeme für Unternehmensanwendungen sind dabei KI-Elemente in ihre Anwendungen zu integrieren. Sie umfassen im Wesentlichen dieselben Leistungen wie die Microsoft-Bürosoftware, heben aber gezielter auf die geschäftlichen Besonderheiten der Unternehmen ab, z.B. durch Analysen der Kundenkontakthistorie in Verbindung mit den Daten, die die Produkte oder Services der Unternehmen beschreiben.
Kritik
Die vielen Anwendungsmöglichkeiten mit den erhofften Beiträgen zu einer erhöhten Produktivität können nicht darüber hinwegtäuschen, dass es auch eine Menge kritischer Punkte gibt.
Überwachungseignung
Die Chatbots einschließlich ihrer firmenspezifischen Anpassungen und die in größeren Systemen eingebauten auf Neuronalen Netzen beruhenden Funktionen haben allesamt die Eigenschaft, das Verhalten der Benutzerinnen und Benutzer zu speichern, zu analysieren und für ihre Antworten bzw. Lösungen zu verwenden. Sie begründen damit eine erhöhte Überwachungseignung der Systeme. Die Daten können weit über ihre ursprüngliche Zweckbestimmung hinaus verwendet werden. Es gibt schon genug Angebote, solche Daten zu Persönlichkeitsprofilen zu verdichten und für Mitarbeiterbeurteilungen zu verwenden. Die fortschreitende Digitalisierung liefert auch die Grundlage für die bessere Verbindung von Anwendungen, die für sich betrachtet schon über eine hohe Überwachungseignung verfügen, wodurch diese nochmals eine deutliche Steigerung erfährt. Das chinesische Social-Scroring-System der punktmäßigen Verhaltensbewertung der Bürger mag hierfür als Paradebeispiel gelten. Kritische Geister sehen auch bei uns bereits beunruhigende Ansätze einer Entwicklung in diese Richtung.
Nivellierung
Die kurz gehaltenen Antworten der Systeme, deren Auswirkungen auf die Weiterentwicklung der Datenbasis sowie auf die Trainingsmethoden begünstigen einen Prozess, den man Mainstreamisierung nennen kann: Unterschied wird behindert, Gleicheit gefördert, polemisch formuliert Masse statt Klasse. Es ist zu befürchten, dass die Akzeptanz schnell gefundener Informationen begünstigt wird. Dies kann dazu führen, dass Oberflächlichkeit gefördert, Nachdenken tendenziell überflüssig gemacht wird.
In der Folge kann ein Bild von Normalität bzw. normalem Verhalten entstehen, genauer von als normal bewertetem Verhalten, das man als heimliches, nicht transparentes Wertesystem dieser Systeme betrachten kann. Wenn Normalität dann einmal definiert ist, lassen sich Abweichungen von dieser Normalität messen und auch gleich in Bewertungen transferieren.
Zurzeit kann man mit den Systemen Google Bard bzw. Gemini und ChatGPT noch sehr unterschiedliche Erfahrungen machen. Was immer gut funktioniert, sind Antworten auf präzise Sachfragen, Fragen, die keine multidimensionale Komplexität aufweisen. Wenn man aber den Dingen weiter auf den Grund gehen will, wird es mühsam, und man wird oft im Stich gelassen. Das Prompting, allso das Stellen präziser Fragen, will gelernt sein, wenn man nicht in Wiederholschleifen der Antworten landen will. Der Eindruck, dass die Systeme dazu „erzogen“ wurden, es bei einer Tiefgang vermeidenden Oberflächlichkeit bewenden zu lassen, scheint nicht völlig falsch. Die Prognose, dass auch hier Bequemlichkeit sich vor Gründlichkeit durchsetzen wird, fällt nicht schwer. Über die gesellschaftlichen Auswirkungen für den Fall, dass der Grebrauch dieser KI-Tools auf breiter Front genutzt wird, kann man zur Zeit nur spekulieren.
Lange bekannt ist die Kritik an den Social Media-Systemen, dass sie durch ihre Neigung zum Alarmismus Polarisierungen fördern. Es geht schließlich um Aufmerksamkeit. Die Ausnahmen von der Normalität erzielen bekanntermaßen mehr Interesse als das Normale, und Aufmerksamkeit lässt sich in Klickzahlen leicht messen. Klickzahlen bringen für die Systemanbieter Geld. So entsteht ein stark rückgekoppelter Kreislauf. Es ist zu erwarten, dass Menschen noch stärker an die Bildschirme der Computer gebunden werden, mit den bekannten Schäden für Aufmerksamkeit und Konzentrationsfähigkeit.
Wege ins Betreute Arbeiten
Die Systeme neigen weiter dazu, ihren Benutzerinnen und Benutzern Vorschläge für ihr weiteres Verhalten oder Tun zu unterbreiten. Ex-Google-Chef Eric Schmidt hat schon vor Jahren darauf hingewiesen, dass man bemüht sei, die Kundschaft nicht nur in der Suche zu unterstützen, sondern ihnen gleich zu zeigen, was sie finden wollen. Anwendungssysteme greifen diesen Trend auf und gehen noch einen Schritt weiter. Sie wollen den Menschen nicht nur „relevante Informationen“ zu ihrer Arbeit geben, sondern bei Gelegenheit auch noch sagen, was sie als nächstes zu tun haben. Der Trend geht zum „betreuten Arbeiten“ . Die Unternehmen müssen sich fragen, ob sie das wollen und wo dabei die vielzitierte Kreativität bleibt.
Fake News
Vor allem dank der KI-Chatbots wird die Menge an erzeugten Informationen stark erhöht werden und sich durch hohe Wiederholungsraten auszeichnen. Informationen, egal ob richtig oder falsch, werden plausibel und breit gestreut im Netz platziert werden können, sodass kaum jemand in der Lage sein wird, zu erkennen, ob das mit den Fakten in der realen, nicht-digitalen Welt übereinstimmt. Fiktion und Realität miteinander zu verschmelzen funktioniert bereits seit längerer Zeit, und die neuen Systeme werden vermutlich wie ein Multiplikator wirken.
Es wird allgemein befürchtet, dass die Menge der Fake News zunehmen wird, denn vor allem die Chatbots erleichtern deren Produktion ungemein. Gleichzeitig wird das Erkennen, dass es sich um Fake News handelt, immer schwieriger.
Halluzinationen
Wenn Anfragen zu weit von der Trainings-Domain der Systeme entfernt sind, tendieren die bisher realisierten Systeme zu Halluzinationen. Sie erkennen die Grenzen ihrer Kompetenz nicht. Es besteht eine hohe Schwierigkeit, diese Grenzen zu bestimmen oder gar zu messen. Die Systeme formulieren ihre Ergebnisse in diesen Bereichen in Form von Aussagesätzen, die mit Bestimmtheit vorgetragen werden, selbst wenn das Ergebnis aus Fake News erzeugt wurde. Dies wird dann von den Benutzerinnen und Benutzer leicht als Objektivität angesehen.
Gleiche Effekte können durch die Verzerrungen in den Trainingsdaten entstehen und führen in eine Art Kompetenzfalle KI-generierter Inhalte, die sich besonders nachhaltig und effektiv festsetzen. Dafür sorgen psychologische Mechanismen, die tief in uns verankert sind.
KI-Systeme zeigen keine sprachlichen Indizien für Ungewissheit. Sie geben überzeugende, flüssige Antworten ohne Hinweise auf Unsicherheiten. Auf das Problem, Schwarze per se als weniger rehabilitierbar anzusehen, haben wir bereits hingewiesen. Wenn nun Richter diese KI-Systeme als kompetent ansehen, kann das dazu führen, dass sie diese Einschätzungen mit der Zeit selbst verinnerlichen.
Die mangelnde Transparenz von KI-Systemen[32] birgt die Gefahr der Entwicklung eines nicht mehr erklärbaren heimlichen Wertesystems.
Die dunkle Seite des Trainings
Die Trainigsmethoden der großen Anbieter von Systemen mit Supervised Learning-Methoden sind wegen der Arbeitsbedingungen der Tester in heftige Kritik geraten. Diese Arbeiten wurden beispielsweise von OpenAI an Dienstleister ausgelagert. Deren Beschäftigte mussten täglich hunderte von verstörenden Textpassagen lesen, zu Stundenlöhnen von umgerechnet zwischen 1.5 und 3.5 Euro[33]. Die Inhalte sollen oft Szenen von Gewalt, Kindesmissbrauch, Bestialität, Mord und sexuellem Missbrauch dargestellt haben. Die den Moderatoren versprochene psychologische Betreuung soll nicht stattgefunden haben.
Sicherheitsprobleme
Die mit Security befassten Firmen weisen auf die gestiegene Gefahr für die Sicherheit der Systeme hin. Insbesondere mit Hilfe von Chatbot-Software lassen sich Phishing-Angriffe nicht nur raffinierter gestalten, sondern vor allem besser automatisieren.
Auswirkungen
Die Literatur setzt sich sowohl mit den Chancen als auch den Risiken der Künstlichen Intelligenz auseinander. Die vielgerühmten Vorteile betreffen vor allem die erhoffte explosionsartige Steigerung der Produktivität, die Lockerung des Zwangs, dass die Arbeit an den Betrieb als der Ort des Arbeitens gebunden ist, die Befreiung von monotonen Tätigkeiten durch Automatisierung und die Erschließung völlig neuer Dienste. Doch auch Nachteile sind unübersehbar, hier einige wichtige Punkte:
Drohende Arbeitsplatzverluste
Während Microsoft-Chef Nadella das Milliardeninvestment in OpenAI bekannt gab, kündigte er nahezu zeitgleich die Massenentlassung von 10.000 Beschäftigten an. Sie scheinen für die KI-Revolution, die Nadella prognostiziert, nicht mehr gebraucht zu werden. Namhafte Unternehmensberatungen sagen einen Verlust von mehreren Hundertmillionen Arbeitsplätzen[34] bis zum Ende des Jahrzehnts voraus. 40 Prozent der geleisteten Arbeitsstunden sollen sich durch Künstliche Intelligenz ersetzen lassen, meint jedenfalls Accenture. Zum Jahresende werden Manager gerne von den Unternehmensberatungen befragt, so auch zur Jahreswende 2023/2024 zu ihren Erwartungen bezüglich der Künstlichen Intelligenz. Eindeutiger Spitzenreiter mit über 60 Prozent in allen mir bekannten Umfragen ist die Automatisierung mit der damit verbundenen Kostensenkung.
Aufmerksamkeitsstörungen
Manfred Spitzer behauptet in seinem 2017 erschienenen Buch Cyberkrank, dass die vermehrte Nutzung digitaler Medien zu kognitiven Defiziten führen kann, die sich unter anderem als Probleme mit der Aufmerksamkeit, dem Gedächtnis und dem Lernen bemerkbar machen, u.a. verringerte Sprachentwicklung und ein verringertes Arbeitsgedächtnis seien die Folgen. In späteren Veröffentlichungen (2018 Einsamkeit) konstatiert er Beschädigungen der emotionalen und kognitiven Empathie und abnehmendes Mitgefühl.
Die Corona-Krise hat für große Teile der Beschäftigten die Bindung an den Bildschirm als Arbeitsmittel verstärkt. Die Einbeziehung der LLM-Chatbots (ChatGPT, Bard/Gemini) in vielen Anwendungsbereichen wird vermutlich die Zeit vor dem Bildschirm weiter verlängern, mit den beschriebenen Auswirkungen.
Beschränkungen der Autonomie
Neue Probleme werden entstehen, wenn KI-Programmen beigebracht wird, auch direkt Dinge zu veranlassen oder Vorschläge zu Entscheidungen zu machen und sie umzusetzen. Die Technik dafür steht zur Verfügung und betrifft die Integration der KI-Leistungen mit Workflows. KI kann dann Dinge tun oder veranlassen, die gar nicht geplant waren. Nicht nur Alarmisten wittern hier die Verfolgung eigener Ziele der KI-Technik.
Qualitätsverluste
Die Versuchung, Systemantworten ohne Kontrolle zu übernehmen und Texte zu veröffentlichen wird steigen. Hat man erst einmal zwanzig astreine Texte generiert, dann ist es leicht anzunehmen, dass alle Texte in Ordnung sein werden. Das bekannte Problem dabei ist, dass die Systeme nicht zuverlässig erkennen können, wann sie einen falschen Kontext übernehmen – sei das aus Fehl- oder Falschinformationen oder einfach, weil ein Ungleichgewicht in den Daten herrscht. Das heißt, auch wenn die Texte noch so gut sind, sollten sie niemals ungeprüft verwendet oder gar publiziert werden.
Fragen für ein Unternehmen
Viel Arbeit wird den Unternehmen durch die Softwareanbieter abgenommen. Sie integrieren, teils in überhastetem Tempo, zunehmend KI-Elemente in ihre Softwaresysteme. Unternehmen profitieren davon und können, wenn sie klug sind, sparsam und mit gebotener Skepsis mit den marketingintensiv als Innovationen verkauften Neuerungen umgehen, gemäß der einfachen Leitfrage: Was nützt uns das?
Die Spreu vom Weizen zu trennen ist kein Kunststück, so lange es sich dabei um ein Eins-zu-eins-Verhältnis handelt, wird aber schwierig, wenn sich dieses Verhältnis in Richtung hundert-zu-eins verschiebt. Das ist leider die heutige Situation.
Wenn ein Unternehmen im Wettbewerb Vorteile erzielen will, muss es Ideen entwickeln, wo und wie Künstliche Intelligenz zum Unternehmenserfolg beitragen kann und muss entsprechende Initiativen ergreifen. Da ist für viele Unternehmen das treibende Motiv leider oft die Angst, den Zug zu verpassen, und es werden ziemlich kopflose Pilotprojekte gestartet. Wer das anders machen will, braucht einen Fahrplan.
Geschäftsidee
Am Anfang sollte ein Konzept stehen, in dessen Fokus die Frage steht, wo vor dem Hintergrund des betriebenen Geschäfts Künstliche Intelligenz einen Erfolgsbeitrag leisten kann. Natürlich schaut man dabei zunächst auf die Daten, über die das Unternehmen verfügt: Schwerpunkt Informationen über Produkte und Dienstleistungen, Kunden und Lieferanten, vor allem Historiedaten über das bisherige Geschäft.
Gemischte Teams sind ein Weg: die IT-Leute lassen sich von den Business-Vertretern das Geschäft erklären und umgekehrt erklärt die IT dem Business, was technisch möglich ist, Voraussetzung allerdings, die IT betet nicht nur nach, was Softwareanbieter und Unternehmensberatungen ihr angedient haben.
Jedenfalls sollte am Ende dieser Phase klar sein, was die Aufgabenstellungen für den eventuellen Einsatz der Technik und den Start entsprechender Projekte sind.
Technik
Wie bereits erwähnt, bieten viele KI-Anbieter APIs (Application Programming Interfaces) an, über die sich ihre Produkte mit firmeninternen Anwendungen verbinden lassen. Dies trifft sowohl für die Large Language Models als auch die Chatbots zu. Diese Angebote umfassen bereits heute Möglichkeiten, die firmeneigenen Datenbestände in alleinigem Zugriff des anwendenden Unternehmens zu halten. Einige Anbieter sprechen weiter die Garantie aus, den internen Gebrauch ihrer Systeme nicht in die Trainingsdaten ihrer Systeme aufzunehmen. Aufzuzählen, wer was anbietet, wäre sozusagen im Wochentakt überholt. Deshalb gilt es, den Markt genau zu beobachten. Wird dieser Weg in Erwähnung gezogen, so braucht es Antworten auf folgende Fragen:
- Welche Geschäftsideen haben das Potenzial, durch Künstliche Intelligenz befördert zu werden?
- Über welche Datenbestände verfügt das Unternehmen? In welcher Form liegen diese Daten vor?
- Welche Daten fehlen für erfolgversprechende Projekte? Sind diese Daten beschaffbar? Zu welchen Konditionen?
- Welche Technik ist für die eigenen Zwecke nützlich? Eines der gängigen Large Language Models, ein Open Source- oder ein proprietäres System? Wichtige Kriterien: mit eigenen Datenbeständen nutzbar, Zugriffsschutz realisierbar.
- Wie müssen die Daten aufbereitet werden?
- Welche Werkzeuge fur Aufbereitung der Daten werden benötigt (sog. Tokenizer, Vektordatenbanken)?
- Ist ein Tagging der Daten erforderlich? Welche Tags? Wer soll das tun? Welche Qualifizierungen für die mit diesen Aufgaben betrauten Experten sind erforderlich? Wie werden diese Qualifikationen aufgebaut? Welche Hilfe von außen ist nützlich oder notwendig?
- Wenn man sich dafür entscheidet, interne Dialoge mit den KI-Systemen in die für das Training der Systeme ausgewählten Datenbestände zu übernehmen, stellt der Schutz sowohl der Kunden- als auch der Beschäftigtendaten besondere Anforderungen (Tagging, Filter, Algorithmen, Zugriffsrechte, Auswertungsbegrenzungen). Wie ist dies zu gewährleisten?
- Wie soll das System trainiert werden? Welche Trainingsmethode, wie umfangreich, von wem durchgeführt, wie qualifiziert sind die Tester, wie wird der Lernerfolg des Systems gemessen?
- Wie kann man die Grenzen der Stabilität des Systems bestimmen?
Den Fragen sieht man bereits an, dass sie gegenseitige Abhängigkeiten aufweisen und sich nicht in eine voneinander unabhängige Form bringen lassen.
Organisation
Natürlich liegt die Idee eines Pilotprojektes nahe, eventuell mehrerer Pilotprojekte, hoffentlich nicht alle gleichzeitig, denn Folgeprojekte sollen von den gewonnenen Erkenntnissen und Erfahrungen profitieren. Die Scrum-Methode[35] bietet sich an, allerdings nur wenn man auf den bürokratischen Overhead verzichtet und die zeitliche Taktung nicht zum Dogma erklärt.
Es gilt, eine Mischung von Brainstorming-Phasen und solider Abarbeitung von Aufgaben zu finden, ebenso eine Festlegung, wer, d.h. welche Personengruppen an welchen Abschnitten des Projektverlaufs beteiligt sind. Dieser Stakeholder-Idee folgend ist auch die Rolle der Betriebsräte zu konkretisieren.
Die Projektteams sollten auf die Kommunikation ihrer Arbeit in der Unternehmensöffentlichkeit großen Wert legen.
Qualifizierung
Zielgruppen sind die IT-Mitarbeitenden, die Benutzer und die Nicht-IT-Fachleute in Projektgruppen, alle auf je spezifische Weise.
Schulungs-Schwerpunkte für die Benutzer sind
- Technische Handhabung der Software
- Prompting: wie man Fragen mit Aussicht auf einen brauchbaren Output stellen muss. Training, auf welche Art von Fragen sind Antworten mit hoher Verlässlichkeit zu erwarten, ab wann begibt man sich in die Zone der Halluzinationsgefahr?
- Realistische Einschätzung der Antworten durch Verständnis der Technik, insbes. des Halluzinieren-Phänomens, die Notwendigkeit betonen, Leistungen der Systeme immer zu überprüfen
- Die Schulung sollte inhaltlich Bezug nehmen auf die bisherigen Tätigkeiten im Arbeitsprozess der Schulungsteilnehmer und wie diese durch die KI-Tools unterstützt werden
- Achtsamkeit für den Datenschutz (Mitarbeiterdaten, Geschäftspartnerdaten)
Ein regelmäßiger (anfangs häufigerer, später seltener) Erfahrungsaustausch kann dazu dienen, die Trainingsmethoden neu zu justieren.
Arbeitsplätze
Insbesondere die Verbindung von LLM-Tools mit Workflows stellt ein Automatisierungspotenzial dar, das vor allem textorientierte und repetitive Arbeiten betrifft.
Mann kann das Organigramm des Unternehmens benutzen, um den Durchdringungsgrad der dortigen Tätigkeiten mit der möglichen Nutzung von KI-Tools zu beschreiben und die Einheiten bezüglich der Gefahr des Arbeitsplatzverlustes bewerten. So entstünde eine unternehmensspezifische Landkarte der gefährdeten Arbeitsplätze. Besonderes Augenmerk sollte dabei den Verbindungen von KI-Funktionen mit Workflows in Bezug auf verbleibende Resttätigkeiten gelten.
Unbedingt sollten die Qualifizierungsanforderungen für die Beschäftigten benannt werden, damit diese auch sinnvoll mit den neuen Instrumenten umgehen können. Man sollte sich darauf einstellen, dass neben dem Wegfall textorientierter und repetitiver Arbeiten eine Gefahr für den Arbeitsplatzerhalt darin besteht, bei den verbleibenden Tätigkeiten die KI-Tools nicht qualifiziert anwenden zu können. Allein aus diesem Grund ist Qualifizierung ein wichtiger Baustein des Beschäftigungsschutzes.
Nach wie vor bleibt es Pflicht des Arbeitgebers, sich um Ersatzarbeitsplätze für diejenigen Beschäftigten zu kümmern, deren Arbeitsplätze Opfer der Automatisierung sind[36].
Persönlichkeitsrechte
Der Einsatz von KI-Tools ist mit einer beachtlichen Steigerung der Überwachungseignung verbunden; dies betrifft ganz besonders diejenigen Tools, bei denen das Benutzerverhalten für die Steuerung der Arbeit verwendet wird. Diese Daten können leicht jenseits ihres Zwecks der Arbeitssteuerung verwendet werden, wie schon beispielhaft das M365-Paket mit seinen eingebauten Funktionen zur Produktivitätsmessung[37] und Compliance-Überwachung[38] zeigt. Außerdem ändern sich durch den Einsatz der Tools Arbeitsbedingungen und Arbeitsablauf. Dies sind klassische Themen für die Behandlung in Betriebsvereinbarungen. Es gibt einige Besonderheiten, die Beachtung verdienen.
- Die KI-Chatbots speichern neben den Daten über das Benutzerverhalten auch die Dialoghistorie. Es sollte sichergestellt sein, dass auf eine Auswertung der Interaktionsdaten (Häufigkeit, Dauer der Nutzung) verzichtet wird und ausschließlich die betroffenen Personen Zugriff auf die von ihnen geführten Dialoge haben.
- Soweit die Systeme Transkriptionen des gesprochenen Wortes und textliche Zusammenfassungen von Meetings anbieten, sollte durch die Basiseinstellung der Systeme gewährleistet sein, dass die Funktionalität aktiv eingeschaltet werden muss. Die Einschaltung in Meetings sollte der vorherigen Ankündigung bedürfen und an das Einverständnis aller Teilnehmenden gebunden sein. Die Sensitivitätsstufen entlang der Kette Brief - Mail - Chat - gesprochenes Wort sind bekannt; bei der Sprache ist die Achtsamkeit am geringsten, denn die einzige Speicherung ist das Gedächtnis der teilnehmenden Personen. Das Verhalten der an einem Meeting Teilnehmenden wird sich verändern, wenn bekannt ist, dass alles was gesprochen wird, auch aufgezeichnet, in Text verwandelt und beliebig verschickt werden kann.
Es gibt einige durch KI ermöglichte Anwendungsfelder, bei denen man überlegen sollte, ob man sie im unternehmensinternen Gebrauch nicht lieber gänzlich ausschaltet. Dazu gehören
- Systeme mit automatisierter Gesichts- und Spracherkennung außerhalb der Berechtigungsüberprüfung (Login),
- Systeme mit KI-gestützter Stimmanalyse oder Analyse der Körpersprache (sog. Sentimentanalyse, andere Formen der Spracherkennung, insbesondere des Affective Computing, Emotionsscanner in Chatfunktionen),
- Funktionen zur Mustererkennung bezogen auf das Verhalten der Mitarbeitenden in Anwendungssystemen (um z.B. abweichendes Verhalten feststellen zu können),
- Verbindungen von KI-Funktionen mit Workflows, bei denen automatische Entscheidungen mit Funktionen verbunden sind, die für direkte Ausführung sorgen. Es sollte Grundsatz bleiben, dass der Beitrag von KI-Funktionen auf Handlungsvorschläge begrenzt und die Ausführung dispositiver und mit Entscheidungen verbundener Tätigkeiten bei Menschen bleibt.
Zusammenfassung
Im derzeitigen Fokus der Künstlichen Intelligenz stehen die Neuronalen Netze. In deren Software wird versucht nachzubauen, was im Gehirn geschieht, und anbetracht der immensen Einschränkungen mit schon bemerkenswertem Erfolg. Die Chatbots haben durch das Vorpreschen von Microsoft mit ChatGPT die Künstliche Intelligenz in die Alltäglichkeit des öffentlichen Bewusstseins gerückt. Elemente dieser KI werden jetzt sukzessive in nahezu alle Softwareprodukte eingebaut. Kaum ein Gesellschaftsbereich bleibt von den neuen Anwendungsmöglichkeiten ausgeschlossen.
Als Vorteile werden neben bisher neuen Anwendungen enorme Arbeitserleichterungen durch die Automatisierbarkeit vor allem repetitiver Tätigkeiten gesehen. Auf der anderen Seite droht der schleichende Wegfall dieser Tätigkeiten. Die derzeitigen Systeme haben noch eine Menge Probleme. Diese liegen in der Auswahl der Daten für das Training, die Verzerrungen enthalten können, ferner in der Unsicherheit der Systemantworten. Auch eine noch so große Datenmenge bildet nicht alle Situationen der Realität repräsentativ ab, und die Systeme tun sich schwer, diese Grenze zu erkennen. Sie neigen dann zu „Halluzinationen“.
Es ist zu befürchten, dass die Flut von Informationen und deren Wiederholrate stark steigen und dass das Informationsniveau gleichförmiger und oberflächlicher wird. Die Grenzen zwischen Vorschlag und Entscheidung werden fließend. Viele Systeme versuchen schon jetzt, den Benutzern zu sagen, was sie tun sollen, der Einstieg ins betreute Arbeiten.
Wenn Unternehmen die Vorteile der Künstlichen Intelligenz erfolgreich nutzen wollen, müssen sie klare Zielvorstellungen für den Einsatzbereich entwickeln, die geeigneten Modelle und Tools auswählen und die Trainigsdaten der Systeme mit eigenen Daten verbinden können. Sie müssen für die erforderliche Qualifizierung ihrer Mitarbeitenden auf allen Ebenen sorgen und ebenso für die Transparenz ihrer Entwicklungsarbeit.
Bei allen Bemühungen um eine fortschrittliche Technik darf man den Schutz der Persönlichkeitsrechte nicht aus dem Auge verlieren, denn die gesteigerte Datensammlung ist mit einer enormen Zunahme der Überwachungseignung verbunden. Es ist weder notwendig noch sinnvoll, alles zu machen, was technisch möglich ist. Deshalb sollten kritische Anwendungen, insbesondere aus der Rubrik der Sentimentanalyse, innerhalb der Unternehmen definitiv ausgeschlossen werden. Eine erfolgreiche Nutzung bedingt eine von Vertrauen getragene Unternehmenskultur. Angst der Beschäftigten dagegen wird die Akzeptanz der neuen Arbeitsformen beschädigen, wenn nicht sogar zerstören.
Anmerkungen
- Goldman Sachs Prognose Augusst 2023
- Z. B. das Perceptron von Frank Rosenblatt
- Vaswani et al. , Attention is All You Need, arXiv 12.6.2027, wenig später in der Zeitschrift Neural Information Processing Systems (NIPS) veröffentlicht
- Das Acronym ERNIE steht für Enhanced Representation though Knowledge Integration.
- DNA steht für Desoxyribonukleinsäure. Es ist ein langes, fadenförmiges Molekül, das aus zwei Strängen besteht, die umeinander gewunden und miteinander verbunden sind und das genetische Material enthalten.
- Wichtige bildgebende Verfahren sind die Funktionelle Magnetresonanztumographie (fMRT), die Positronen-Emissions-Tomographie (PET) sowie die Magnetoenzephalographie (MEG).
- Ionen sind Atome, die in ihrer Elektronenhülle ein Atom verloren (posities Ion) oder hinzugewonnen (negatives Ion) haben.
- Das elektrische „Klima“ ist mit dem Wert von minus 70 milliVolt (- 70mV) innerhalb der Neuronen also sehr mild. Zum Vergleich: eine kleine Triple-A-Batterie hat eine Spannung von +1500 mV.
- Wer genauer wissen will, wie die Natrium-Kalium-Pumpe funktioniert, hier eine kurze Erklärung: Die Na-K-Pumpe ist ein in der Zellmembran des Neurons vorkommendes Protein-Molekül. Es enthält Adenosin-Triphosphat (ATP), ein Molekül, das Ernergie speichern kann; seine chemische Summenformel ist C10H16N5O13P3. Die Pumpe bindet zuerst drei Na+-Ionen, dann ein ATP-Molekül und hydrolysiert es, d.h. es wird gespalten. Die aus diesem Vorgang gewonnene Energie wird benutzt, um drei Natrium-Ionen gegen ihre höhere Konzentration in der Umgebung der Zelle aus der Zelle herauszubefördern. Nachdem dies geschehen ist, bindet die Pumpe zwei Kalium-Ionen an sich, löst sich wieder vom ATP und den drei Natrium-Ionen und transportiert die zwei Kalium-Ionen entgegen ihrer in der Zelle im Vergleich zu ihrer Umgebung höhere Konzentration in die Zelle hinein. Kürzer ging die Erklärung nicht.
- Alec Radford, Karthik Narasimhan, Tim Salismans, Ilka Sutskever: Improving Language Understanding by Generative Pre-Training, OpenAI 2018
- Die Universität Ulm stellt einen Link zum sog. D-Faktor-Test zur Verfügung, wer ihn ausprobieren will bitte hier klicken.
- Wenn die Lernkurve der Testdaten rapide steigt und die Lernkurve der Trainingsdaten sinkt, dann hat man einen Hinweis für das Auswendiglernen. Dann hilft nur noch der Griff zur Notbremse des Early Stopping.
- Ein Hersteller bezeichnen den Aufwand für die Bearbeitung eines Eingabesignals mit bis zu 10 Milliarden Rechenoperationen.
- Das kostenfreie ChatGPT kann z.B. auf keine Daten zugreifen, die nach September 2021 liegen (Stand Oktober 2023).
- Chen, Lingjiao, Zachharia, Matei, Zou, James: How is ChatGPT's Behavior Changig over Time? , airXiv 2307.09009v2.
- Lesenswert: Ralf Otte: Maschinenbewusstsein, Frankfurt 2021
- Kagen, Brett J., Kitchen, Antony C. et al., Projekt Dishbrain, Monash University, Melbourne
- Die Speichereinheiten normaler Computer können nur die Werte 0 oder 1 annehmen. Die Quantencomputer machen sich die Errungenschaften der Quantenphysik zunutze, ihre Speichereinheiten, die sogenannten Qubits, können gleichzeitig die Werte 0 und 1 annehmen und damit parallell erfolgende Verarbeitungen möglich machen, während normale Computer strikt sequenziell arbeiten müssen. Diese Eigenschaft ermöglicht einen großen Geschwindigkeitsvorteil gegenüber normalen Computerm, stellt aber keinen qualitativen Sprung in neue Dimensionen künstlicher Intelligenz dar. Ihr Betrieb ist extrem teuer und ihre Fehleranfälligkeit noch sehr hoch.
- Alan Blackwell, Universsität Cambridge, zitiert nach Matt Asai: So dämmen Sie KI-Bullshit ein, Computerwoche online vom 21.11.2023
- Fei-Fei Li leitete von Januar 2017 bis Oktober 2018 Forschung und Entwicklung von Google Cloud im Bereich Künstliche Intelligenz, ist heute Professorin für Informatik an der Stanford University.
- Nur so zum Spaß: 20 Watt Leistung eines menschlichen Gehirns entspricht rund 175 kWh pro Jahr. Für die ganze Menschheit sind das dann 1.7 Billionen kWh pro Jahr. Der Energieverbrauch der Computer weltweit wird auf 1.8 Billionen kWh pro Jahr geschätzt, sagt Google Bard, ChatGPT meint 1.5 Billionen kWh/a für das Jahr 2020.
- Es ist schwer, sich hier sachkundig zu machen. Man müsste eine Standardsituation beschreiben. Wer sich für die CO2-Footprints interssiert, kann sich bei Oeku.eu umsehen.
- Anfrage Google Bard vom 11.9.2022.
- Steigerungsraten dank leistungsfähiger gewordener Computer angeblich von 20 auf fünf Prozent zurückgegangen, sagt Bard.
- Kay Nordenbrock: Apple hat heimlich ein großes Sprachmodell als Open-Source-Code veröffentlicht, t:n vom 27.12.2023.
- Tobias Költzsch: ChatGPT liest künftig die Bild, 13.12.2023, golem.de
- Wer sich gerne einmal von einem Chatbot beschimpfen lassen will, kann es hier ausprobieren.
- Die Akronyme B2B und B2C stehen für Business-to-business- bzw. Business-to-customer-Anwendungen.
- Albert Einstein wird sich sicher im Grab herumdrehen, sollte er erfahren, was mit seinem Namen angestellt worden ist.
- DAS SAP-LLM arbeitet mit 137 Milliarden Parametern.
- Nuance Communications GmbH, Aachen, von Microsoft 2022 übernommen, Manager Magazin vom 26.5.2023.
- Wegen ihrer Intransparenz bezüglich ihrer internen Methoden werden diese Systeme in der Literatur oft als opak bezeichnet.
- Beatrice Nolan, Moderatoren, die Inhalte für ChatGPT geprüft haben, sagen, sie sind von ihrer Arbeit traumatisiert: „Es hat mich völlig zerstört“, BusinessInsider vom 4.8.2023.
- Prognose von Goldman Sachs 300 Millionen Arbeitsplätze, die bis Ender der 2020er Jahre verloren gehen.
- Eine „agile“ Methode, um in kurzen „sprints“ genannten Zyklen mit besonderen Rollen, speziellen Hilfsmitteln und installierten Feedbacks ein funktionsfähiges System zu erstellen.
- In früheren betrieblichen Regelungen wurde unter dem Titel Mischarbeitsplätze darauf geachtet, dass es einen angemessenen Belastungs- und Beanspruchungsmix durch verschiedene einem Arbeitsplatz zugewiesene Tätigkeiten gab. Dies war auch aus Sicht des Gesundheitsschutzes förderlich. Solche Konstruktionen haben sich als wesentlich robuster in Bezug auf den drohenden Wegfall des Arbeitsplatzes erwiesen.
- Ehemals myAnalytics und WorkplaceAnalytics, später dann in Viva integriert.
- vgl. Microsoft 365 Änderungen vom September 2022.
Hamburg, im November 2023, Update Juni 2024
 |
tse • Dr. Karl Schmitz | Dezember 2023/Januar 2024 |
 tse Hamburg
tse Hamburg |
432 / 5827 |