 Chatbots, Sprachmodelle und Neuronale Netze
Chatbots, Sprachmodelle und Neuronale Netze
ChatGPT hat die Künstliche Intelligenz in die Aufmerksamkeit der ganzen Welt befördert. Hinter dem freundlichen Unterhaltugsprogramm steckt ein mächtiges Sprachmodell, dessen Basistechnik ein Neuronales Netz ist. Hier das Wichtigste so kurz wie es geht:
Die Idee der KI-Technik ist alles andere als neu, sie geht auf die 1940er Jahre zurück und hatte danach eine lange Durststrecke.
1943 veröffentlichten der Neurophysiologe Warren McCulloch und der Mathematiker Walter Pitts den Artikel „A Logical Calculus of the Ideas Immanent in Nervous Activity“, in dem sie ein mathematisches Modell von Neuronen vorstellten. Dieses Modell gilt als die erste formale Beschreibung eines neuronalen Netzes.
Vielen gilt allerdings das Dartmouth Summer Reseach-Projekt von 1956 als Beginn der Künstlichen Intelligenz, ein Treffen junger Wissenschaftler, die eine Maschine bauen wollten, die das tun kann, was man üblicherweise menschlicher Intelligenz zuschreibt.
Das erste wirklich funktionierende Neuronale Netzt war 2012 das AlexNet unter Beteiligung des späteren Npbelpreisterägers von 2024, Geoffrey Hinton.
Die KI-Technik ist erst in den letzten Jahren so erfolgreich, weil man heute über riesige Mengen von Daten und damals nicht vorstellbare Computer-Power verfügt.
Die Idee der Neuronalen Netze besteht darin, nachzubauen, was wir über die Vorgänge in unserem Gehirn wissen - oder zu wissen glauben.
Das menschliche Gehirn
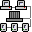
Unser Gehirn, genauer die Großhirnrinde, verfügt über rund 100 Milliarden besondere Nervenzellen, die sog. Neurone. Sie sind für die Signalübertragung untereinander durch besondere Nervenbahnen verbunden, die Dentriten für einkommende Signale und die Axone für ausgehende Signale. Jedes Neuron kann bis zu 1000 solcher Verbindungen haben, das macht dann insgesamt rund eine Billion. Diese Verbindungen sind surch die sog. Synapsen unterbrochen. Hier entscheidet sich, ob ein Impuls verstärkt oder abgeschwächt wird.
Skizze eines biologischen Neurons und einer seiner Verbindungen
mehr erklären
Ein Neuron wird aktiv, wenn es einen genügend starken elektrischen Impuls erhält, der es aus seinem Ruhepotenzial von ca. -70 mV „aufweckt“. Diese Impulse können von den Sinnesorganen (sehen, hören, fühlen usw.), anderen Neuronen oder vom Gehirn selber erzeugt sein, beispielsweise durch simples Nachdenken. Wenn ein Neuron aktiviert wird, sendet es seinerseits über seine zahlreichen Verbindungen Signale aus. Im Fachjargon heißt das dann: es feuert.
Bei allem, was im Gehirn mit den Neuronen passiert, handelt es sich nie um Einzeltäter, sondern sie sind immer in großen Massen, zu Tausenden oder Zehntausenden, in Ausnahmefällen sogar Millionen an ihren Aktionen beteiligt, alle gleichzeitig.
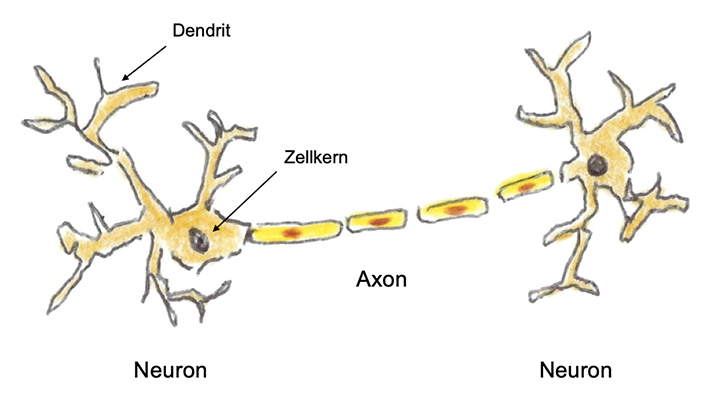
Reizübertragung
durch den Synaptischen Spalt
Die Axone sind keine direkten Leitungen, sondern durch Synapsen unterbrochen. Hier verfügen die Axon-Enden über Eigenschaften, sog. Neurotransmitter, auszuschütten. Diese können die Leitungslücke in dem synaptischen Spalt überwinden und am anderen Ende wieder einen elektrischen Impuls weiterleiten. Es gibt hunderte verschiedener Neurotransmitter, spezialisiert auf besondere Reize, die wir Menschen dann als Emotionen wie Freude, Lust, Schmerz, Angst, Trauer, Stress usw. empfinden können. Diese Botenstoffe können dafür sorgen, dass in der Synapse die angekommenen Reize verstärkt, abgeschwächt oder ganz unterdrückt werden. Dies erfolgt in kleinen und kleinsten Schritten, immer ein bisschen Umbau durch die Bildung neuer Rezeptoren für die Neurotransmitter oder durch deren Abbau, alles durch Wiederholungen verstärkt, bis ein für einige Zeit stabiler Zustand erreicht wird.
Dieser Langzeitpotenzierung genannte Vorgang ist die Grundlage für Lernen und Gedächtnis und ist auch daran beteiligt, dass alte Informatonen „vergessen“ werden können. Die Gesamtheit dieser Veränderungen macht die Plastizität des Gehirns aus, die uns normalerweise bis ins hohe Alter erhalten bleibt. Trotz intensiver Forschung ist unser Wissen um diese Vorgänge nur sehr oberflächlich. Wir können die Reize im Gehirn verfolgen, Areale ausmachen, die für besondere Eigenschaften wie Sehen, Sprache, Hören, Motorik genutzt werden, haben aber buchstäblich keine Ahnung, wie aus den Reizen subjektive Empfindungen und Gefühle oder gar Bewusstsein entsteht. Dann ist immer die Rede von den neuronalen Korrelaten, die nur besagen, dass ein bestimmter visueller Cortex genannter Bereich mit dem Sehen verbunden ist oder Aktivitäten in den beiden Hippocampi für die Bildung und den Abruf von Erinnerungen in Zusammenhang gebracht werden. Aber wie das genau funktioniert, wissen wir nicht.
Computergehirne
Die Mimik des menschlichen Gehirns versucht man nun technisch nachzubauen. Kein Computer hat tatsächlich Neurone, alles wird nur softwaretechnisch simuliert. Dies gilt auch für die Synapsen, die als Verbindungswerte bzw. Parameter gespeichert werden. OpenAIs Spitzenmodell soll davon schätzungsweise 100 Billionen haben. Alles ist etwas eindimensional, die künstlichen Synapsen verfügen nicht über die Vielfalt der Botenstoffe im menschlichen Gehirn.
Neuronale Netze sind also Softwaremodelle. Sie sind in mehreren Schichten organisiert, haben eine Input-Schicht für die Aufnahme der geforderten Informationen, eine Ausgabeschicht für ihre Ergebnisse und dazwischen beliebig viele vorborgene Schichten, die sog. hidden layers, unterschiedlich je nach Art und Aufgabe des Netzes. Es gibt sehr verschiedene Konstruktionen, bekannt als Netzwerk-Topologien.
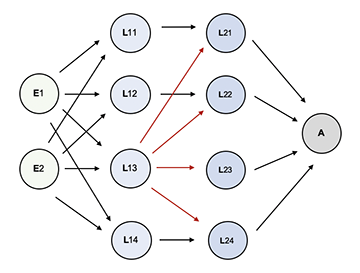
Schematischer Aufbau eines einfachen Neuronalen Netzes
mit zwei Eingabeneuronen (E), zwei hidden layers (L) mit je vier Neuronen und einem Ausgabeneuron (A).
Es gibt sehr unterschiedliche Topologien. Am bekanntetsten sind die Transformer-Modelle. Sie haben Hunderte bis Tausende hidden layers und sind die Grundlage der Chatbots wie ChatGPT von OpenAI, Gemini von Google, Claude von Anthropic, Meta AI (Facebook) oder Grok von Elon Musks X, um nur die derzeit Wichtigsten zu nennen. Die Abkürzung GPT steht für Generative Pretrained Transformer, also vortrainierte Systeme. Sie alle arbeiten mit sog. Large Language Models, abkekürzt LLM. Sie müssen trainiert werden.
Training
Für das Training wird eine riesige Datenmenge ausgewählt. Bei den bekannten großen Systemen sind das Milliarden bis Billionen Datensätze. Nur ein Teil dieser Daten wird für das direkte Training verwendet, mit dem Rest der Daten wird das System dann später getestet. Es gibt sehr verschiedene Trainingsmethoden. Sie unterscheiden sich in den folgenden Merkmalen:
- Datenauswahl: Für die Aufgabenstellung des Systems soll man repräsentative Daten auswählen. Das ist natürlich für spezielle Systeme, z.B. medizinische Diagnosen, relativ einfach, für Chatbots wie ChatGPT oder Gemini aber schwierig, weil sie ja für nahezu alles und jedes Auskunft und Antwort geben müssen.
- Aufbereitung: Die Daten werden dann bereinigt und in eine computerlesbare Form gebracht. Hier gibt es verschiedene Verfahren. Diesen Vorgang nennt sich Vektorisierung.
- Training: Eine bekannte Trainigsmethode ist die Verwendung von Frage-Antwort-Paaren, die in großer Zahl von Experten entwickelt wurden. Man nimmt eine Teilmenge der Trainingsdaten, setzt die Verbindungswerte der Neuronen auf einen Anfangswert und lässt das System suchen, was die aufgrund der statistischen Auswertung der Trainingsdaten die wahrscheinlichste Antwort auf die Frage wäre.
- Wiederholung: Das Ganze wird - je nach System - millionen- bis milliardenfach wiederholt. Eine der bekannten Fehlerfunktionen lässt man entscheiden, ob das Ergebnis sich gegenüber dem vorangegangenen Ergebnis verbessert oder verschlechtert hat. Davon abhängig werden die Verbindungswerte, wiederum gesteuert durch eine mathematische Funktion - ein klein wenig verändert.
- Test: Wenn die Änderungen nach einem Trainings-Step eine vorgegebene Fehlergrenze unterschritten haben, wird das Training abgebrochen und mit den Daten der gesamten Trainings-Domain getestet, bis man mit dem Ergebnis zufrieden ist.
- Filterung: Besondere Algorithmen sollen dafür sorgen, dass beleidigende, Gewalt verherrlichende oder zu Verbrechen auffordernde Ergebnisse unterdrückt werden (Vermeidung oder Abschwächung sog. BIAS) oder die Antworten irgendwie nach Auffassung des Systenbetreibers political correct sind.
mehr erklären
Eine ausführlicher Erklärung zum Training findet sich hier.
Die bekanntesten Trainingsmethoden sind
- Überwachtes Lernen (Supervised Learning): Für vorher ausgewählte Eingabe- und Ausgabemuster kennt das System für jeden Input den „richtigen“ Output und vergleicht in jedem einzelnen Trainingsschritt das vorhergesagte Ergebnis mit dem „richtigen“ Ergebnis. Es ändert dann die Gewichte zwischen den Neuronen selbständig gemäß bestimmter Verfahren (sog. Loss-Funktionen) und lernt so die Eingabemuster mit den gewünschten Ausgabemustern mit jedem Schritt besser zu verbinden. Dabei ist es nützlich, wenn die Daten gelabelt sind, d.h. jedes Datenbeispiel in den Trainingsdaten mit besonderen Merkmalen näher beschrieben ist.
- Unüberwachtes Lernen (Unsupervised Learning): Das Netz erhält keine Eingabehilfen und muss versuchen, selbst Muster oder Eigenschaften in den Daten zu finden, ohne vorher zu wissen, wonach es suchen soll.
- Bestärkendes Lernen (Reinforcement Learning): Das Netz erhält im Vergleich zum überwachten Lernen deutlich weniger Informationen. Es muss die passende Kategorisierung der Eingabe selber herausfinden und erhält nach jedem Durchlauf entweder durch Experten oder maschinell nur die Information, ob sich die Richtigkeit des Outputs verbessert oder verschlechtert hat. Aufgrund dieser Information ändert es die Gewichte zwischen den Neuronen, ebenfalls nach bestimmten, je nach Verwendungszweck des Netzes unterschiedlichen Verfahren.
Bei der zuletzt genannten Methode kann sich natürlich kein Systemanbieter leisten, Milliarden Antworten von menschlichen Experten bewerten zu lassen. Hier begnügt man sich mit einer kleinen Auswahl, verwendet dann diese bewerteten Antworten als neues Trainingsmaterial. So soll den Systemen beigebracht werden, die an ausgewählten Frage-Antwort-Paaren trainierten Bewertungen für beliebige andere Statements vorherzusagen. Mehr dazu hier.
Im Vergleich mit der menschlichen Intelligenzleistung fallen doch riesige Unterschiede auf:
- Langsames Lernen: Im Vergleich zu uns Menschen lernen Neuronale Netze trotz der enorm hohen Leistungsfähigkeit der Computer sehr langsam. Ein Kind ist in der Regel nach einer Million gesprochener Sätze in der Lage, einen beliebigen Satz richtig formulieren zu können, ein Sprachmodell braucht dafür Milliarden Sätze. Das Training der großen Systeme kann Wochen dauern.
- Keine autonome Wahrnehmung: Computer heutiger Bauart können nicht nach draußen sehen und nichts selber, aus eigener Initiative wahrnehmen. Ihnen muss allles von außen beigebracht werden. Man kann sie trainieren, Gefühlsregungen von Menschen zu erkennen, aber sie können selber nichts fühlen.
- Mustererkennung: Darin sind die Systeme unübertroffen. Sie können aus Milliarden, inzwischen Billionen von gespeicherten Informationen Muster erkennen, auch solche, auf die noch kein Mensch je gekommen ist. Viele Technik-Enthusiasten halten dies für Kreativität, stellt aber bei genauerer Betrachtung nur eine neue Kombination bereits dagewesener Dinge dar.
- Kein Bewusstsein: Die großen Sprachmodelle wissen nicht, was sie tun. Sie kommen aufgrund von Statistik und Wahrscheinlichkeitsrechnung, gesteuert durch korrigierende Algorithmen, zu ihren Ergebnissen. Sie können nicht selber denken, haben keinen eigenen Willen und können auch nicht aus eigenem Antrieb handeln.
Immer noch ist das Problem der Halluzinationen nicht zufriedenstellend behoben. Wenn die Systeme bei Fragen oder Anforderungen keine plausiblen Daten in ihren Trainingsdaten finden, müssen sie extrapolieren, merken aber selber nicht, wann sie ihre sicheren Gefilde verlassen. Hier ein krasses Beispiel.
Inzwischen werden Klagen über den Mangel an qualitativen Daten immer lauter. Bei den schon billionenhaft vorhandenen Trainingsdaten stellen neue Daten keinen nennenswerten Qualitätszuwachs mehr dar, zumal jetzt, zwei Jahre nach der Geburt leistungsfähiger Chatbots, schon beachtlich viele öffentlich zugängliche Daten von KI erzeugt wurden (schätzungsweise sind schon fünf Prozent der Wikipedia-Einträge nicht von Menschen geschrieben).
Mit seinem LLM-Distillation-Konzept hat OpenAI eine Methode vorgestellt, wie ein großes Sprachmodell ein kleineres spezialisiertes Sprachmodell trainieren kann. Wenn die Methode sich bewährt, dann wird es auch für kleinere Unternehmen kostengünstig, sich leistungsfähige Chatbots für spezialisierte Einsatzbereiche herzustellen.
Nächste Stufen
Chatbots und ähnliche KI-Programme werden zu Agenten weiterentwickelt, die Sprachmodelle, Chatbots oder klassische Assistenzprogramme mit Workflows verbinden. Sie sollen mehrstufige komplexe Aufgaben mit wenig oder gar keiner menschlichen Unterstützung übernehmen können. Das Ziel ist, intelligente und hochleistungsfähige Assistenten zu schaffen, die Arbeitsaufgaben unabhängig oder mit minimaler menschlicher Aufsicht gemäß vorgegebener Algorithmen planen, begründen und ausführen können.
mehr erklären

Workflow für den Recruiting-Prozess
Die nebenstehende Abbildung (aus einer Vorschlagsskizze von McKinsey) zeigt den Aufbau eines solchen Workflows am Beispiel des Recruiting-Prozesses:
Die Unternehmensberatung Gartner prognostiziert, dass bis 2028 ein Drittel der Unternehmensanwendungen „agentic AI“ enthalten wird, gegenüber weniger als einem Prozent im Jahr 2024. Die Agenten werden in digitale Arbeitsanwendungen integriert, mit denen eine Vielzahl von Büroangestellten regelmäßig arbeitet.
Eine bekannte Unternehmensberatung schildert ein Beispiel dafür, wie ein solcher Agent in die Gestaltung von Kundengesprächen integriert werden könnte. Der Workflow wird aktiviert, sobald eine Kunden-E-Mail eingeht. Der Agent sammelt die relevanten Details aus den früheren E-Mails, überprüft frühere Interaktionen, fasst die Kundenbedürfnisse zusammen und ermittelt die richtige Mitarbeiterin bzw. den Mitarbeiter für das Treffen mit dem Kunden nach Durchsuchen der Skillprofile und persönlichen Kalender. Die ausgewählte Person erhält die Auftrags-Order mit einer Zusammenfassung der relevanten Kundendaten und sendet nach Bestätigung eine Einladung an den Kunden.
Man soll dann auch Mitarbeitenden Tools zur Verfügung stellen können, sich für ihre Aufgabengebiete solche Agenten selber zusammenbasteln zu können. Viele Tools erfordern dazu wenig bis gar keine IT-Fachkenntnisse. Alles soll mit LowCode- oder NoCode-Werkzeugen bewerkstelligt werden können. Analysten von International Data Corporation (IDC) prognostizieren, dass ein Fünftel der sog. Wissensarbeiter ohne Entwicklungserfahrung bis Ende 2025 ihre eigenen, agentenbasierten Arbeitsabläufe erstellen werden. Aufgaben, Prozesse, Probleme und Ziele werden dann in einfacher Sprache beschrieben und von den Agenten in Code, Skripte oder Automatisierungsroutinen umgewandelt.
Vorerst traut man sich noch nicht, KI-Agenten komplexere Aufgaben ganz ohne menschliche Aufsicht ausführen zu lassen, doch das wird sich, gestuft nach Risikogruppen - wahrscheinlich schnell ändern.
Die KI-Agenten sollen nicht nur Fragen in Chatfenstern beantworten, sondern selbstständig Aufgaben erledigen wie z.B. eigenständig im Internet suchen, Flüge buchen, E-Mails schreiben, Verträge abschließen oder auch bloß Dinge übernehmen, die den Nutzern lästig sind. Die Kommunikation erfolgt über Sprache, eingebettet in freundlichen Smalltalk. So kann das System die Stimmungslage seines Benutzers besser erkennen und sich ihm als Freund oder Partner andienen. Die Systeme können zwar selber nichts fühlen. Das ist auch nicht nötig, denn dank ihrer Fähigkeit zu Mustererkennung und aufgrund ihres gründlichen Trainings können sie Gefühle ausreichend gut simulieren. Eine gründlichere Auseinandersetzung mit diesem Thema finden Sie hier.
Dabei können die Agenten sogar in Verbünden arbeiten und selber untereinander ausmachen, welcher Agent welche Arbeit übernimmt. So lässt sich eine Menge Koordinierungsarbeit einsparen.
Die meisten Unternehmen sind für die Umsetzung solcher Projekte allerdings noch schlecht aufgestellt.
mehr erklären
Die Defizite betreffen die Daten, die Technik und die Unternehmenskultur. Die Haupthindernisse sind:
- Die internen Prozesse sind nicht hinreichend präzise definiert. Eine Beurteinung, welche Prozesse mit Produktivitätsgewinn durch KI unterstützt werden können, ist daher schwierig oder findet nicht statt.
- Die Daten sind verstreut in unterschiedlichen Formaten verteilt über das Unternehmen.
- Die Datenqualität ist auf einem zu niedrigen Niveau. Dies trifft sowohl auf Produkte und Services, Kunden und die Beschreibung der internen Abläufe zu.
- Die Softwarelandschaft bietet ein komplexes verschachteltes Bild unterschiedlicher Systeme mit vielen Schnittstellen.
- In der IT fehlt es an KI-Qualifikationen und folglich an Erfahrungen.
- Die Unternehmenskultur ist nicht für die Veränderungen vorbereitet. Dies betrifft die Kommunikation zwischen IT und den Geschäftsbereichen sowie die komplette Belegschaft.
Vielen Unternehmen ist ein Investment in die KI-Technik zu riskant und zu teuer. Die Änderungsrate der Technik wird als zu hoch empfunden. Deshalb lautet vielerorts die Einstellung Abwarten, Dranbleiben um den Zug nicht zu verpassen
Die Folgen
Auch hier ist das eigenständige Handeln der neuen Agenten nur Schein. Mustererkennung funktioniert nicht nur mit Textdokumenten. Man kann Systeme genauso gut auf Handlungsmuster trainieren. Sie können dann erkennen, welche Cluster von Arbeitsabläufen statistisch signifikant zusammen vorkommen. Daraus lassen sich Tätigkeitsprofile entwickeln, die dann den Benutzerinnen und Benutzern vorgeschlagen werden können. Der Umfang der erlaubten Abweichungen von diesen Mustern kann mit fortschreitendem Feintuning immer weiter eingeschränkt werden. So lassen sich Konzepte für Normalität entwickeln. Durch Algorithmen kann die Steuerung weiter beeinflusst werden.
Dank der kleinteiligen Überwachbarkeit aller digitalisierten Vorgänge ist die Kontrolle über die Einhaltung der neuen Normalität kein Problem, denn die Abweichungen von der computerdefinierten Normalität können real time festgestellt, über längere Zeitabschnitte ausgewertet oder mit Alarmfunktionen versehen werden. Im Laufe der Zeit lassen sich durchaus duldbare Abweichungen von den Normalitäts-Vorlagen erkennen und in das Repertoire der Systeme einbeziehen. Und den Menschen wird es gefallen, sagen jedenfalls zahlreiche Prognosen. So wird Schritt für Schritt das Konzept des in seiner Arbeit geführten Menschen in die Tat umgesetzt, bis die Arbeit von den Agent-Verbünden komplett übernommen wird. Neu im Vergleich zu früheren Automatisierungswellen ist: Das kann alles sehr schnell gehen.
Große technische Veränderungen haben immer schon Probleme für gesellschaftliche Anpassungen nach sich gezogen, eindrucksvoll in den Büchern The Coming Wave von Mustafa Suleyman und Nexus von Yuval Noah Harari beschrieben. Auch hier ist neu, dass alles viel zu schnell geht.
Schlussfolgerungen
Betroffen sind die Gesellschaft, die Unternehmen und wir alle als Individuen. Wenn wir uns auf die Unternehmen beschränken, erfordern folgende Aktionsfelder eine besondere Beachtung:
- Beschäftiging: Die möglicherweise von arbeitsplatzeinsparenden Rationalisierungen betroffenen Tätigkeitsfelder sollten identifiziert werden. Auf sie müssen sich Maßnahmen der Personalentwicklung konzentrieren.
- Qualifizierung: Neben „klassischen“ Umschulungen im Rahmen der Personalentwicklung ist es wichtig, dass die Beschäftigten einen selbstbewussten kritischen Umgang mit der KI-Technik erlangen. Dies erforder Transparenz über die Ziele des Unternehmens, umfassende Qualifizierung und vor allem die Bereitstellung von Erfahrungs- und Experimentierräumen.

 tse Hamburg
tse Hamburg